A revolução da cointeligência está remodelando silenciosamente o que significa excelência acadêmica – e quem pode alcançá-la, afirma Jakub Drábik
Fonte: sompong_tom/Getty Images
Por Jakub Drábik para o “Times of Higher Education”
Há uma sensação particular de desânimo com a qual muitos centro-europeus certamente estão familiarizados. Ela surge quando, ao ouvir um acadêmico britânico ou americano em uma conferência ou seminário, você percebe que, não importa quantos livros leia ou quão sólidas sejam suas ideias, você nunca falará ou escreverá em inglês com tanto estilo ou confiança quanto eles.
Fluência nativa na língua franca acadêmica, educação de elite e imersão precoce nas normas acadêmicas lhes dão um tipo de vantagem estrutural — uma com a qual os outros aprendem a conviver, mas que raramente conseguem superar.
Ou assim eu pensava.
Ultimamente, tenho experimentado IA (Inteligência Artificial) generativa – não para terceirizar meu pensamento, mas para aprimorar a forma como o comunico. O resultado? Minha escrita ficou mais rápida, clara e precisa. É uma sensação estranha: ainda sou eu, mas com uma espécie de exoesqueleto intelectual.
Minha experiência — que certamente está longe de ser única — levanta uma questão desconfortável: a regra de ouro da sobrevivência acadêmica — publicar ou perecer — foi agora complementada por outra — IA ou morrer?
Não quero dizer que a IA substituirá os acadêmicos (pelo menos, espero que não). Mas ela pode remodelar fundamentalmente a excelência acadêmica, como ela é alcançada e quem tem o direito de apresentar um desempenho de alto nível. E isso merece uma análise mais aprofundada.
Uma das mudanças mais visíveis trazidas pelas ferramentas de cointeligência é a redistribuição silenciosa do trabalho cognitivo. Tarefas que antes exigiam um esforço meticuloso – reformular frases incômodas, traduzir ideias para o inglês acadêmico, elaborar esboços – agora podem ser semiautomatizadas. Clareza e velocidade não estão mais vinculadas apenas à habilidade pessoal ou à fluência linguística, mas à fluência com que você consegue direcionar e moldar a produção de grandes modelos de linguagem. E se o que atualmente chamamos de “excelência” é, em parte, a capacidade de produzir textos claros e persuasivos com eficiência, então a excelência tem o potencial de ser compartilhada de forma mais equitativa.
No entanto, o impacto da IA na equidade tem limites. Acadêmicos em instituições com poucos recursos podem ter dificuldades para acessar os mesmos benefícios. O mesmo pode acontecer com aqueles que trabalham em idiomas pouco suportados pelos modelos tradicionais de IA. E aqueles que não têm proficiência técnica ou que se incomodam com a ausência de normas claras para o uso da IA também podem ficar para trás.
Em relação a essas normas, todos parecem concordar que o autor deve permanecer responsável pelo conteúdo, independentemente do nível de IA envolvido. Mas não há consenso sobre como integrar essas ferramentas ao processo de escrita ou como – ou mesmo se – reconhecer sua contribuição.
Na minha opinião, a alfabetização em IA deve ser tratada não como um acréscimo técnico, mas como uma competência acadêmica essencial – a par da alfabetização informacional ou da avaliação de fontes. Algumas universidades, especialmente no Reino Unido e nos EUA, já aceitaram isso e estabeleceram programas de alfabetização em IA para ajudar colegas mais cautelosos ou sobrecarregados a acompanhar os pioneiros – a iniciativa da Universidade Estadual do Arizonaé frequentemente citada.
Mas outras instituições, particularmente na Europa Central e Oriental, permanecem hesitantes, ainda considerando o uso da IA como suspeito ou até mesmo antiético. Alguns periódicos e conselhos de ética também têm se mostrado cautelosos. E em meio a tanta incerteza, a política não oficial passou a ser: use se quiser, mas não fale sobre isso em voz alta – pelo menos, não em reuniões.
Mas se aceitarmos, como devemos, que o uso da IA é inevitável, precisamos lidar com a questão fundamental do que, exatamente, ainda é “nosso” no trabalho que produzimos quando a formulação, a estrutura e até mesmo parte da estrutura intelectual são cogeradas com a IA.
Como argumentaram filósofos da tecnologia, comoShannon Vallor ouDavid J. Gunkel, o conhecimento coproduzido desafia a estrutura profundamente individualista da autoria, na qual se baseia o prestígio acadêmico. Talvez também precisemos repensar os conceitos de originalidade e até mesmo de contribuição intelectual.
Centrá-los em síntese, julgamento e direção pode fazer sentido, mas não tenho respostas. Aliás, nem tenho certeza se compreendo completamente o terreno em que estamos entrando. Mas se não mantivermos os olhos abertos e nos envolvermos com as implicações de para onde estamos indo – éticas, pedagógicas e institucionais –, podemos descobrir que não apenas a distribuição, mas o próprio significado da excelência acadêmica já mudou, enquanto ainda estamos discutindo se deveria mudar.
Jakub Drábik é professor de história na Universidade Anglo-Americana de Praga e pesquisador sênior no Instituto de História da Academia Eslovaca de Ciências
Artigos falsos estão alimentando uma indústria corrupta e retardando pesquisas médicas legítimas que salvam vidas
Por Frederik Joelving, Cyril Labbé e Guillaume Cabanac, para The Conversation
Na última década, entidades comerciais furtivas ao redor do mundo industrializaram a produção, venda e disseminação de pesquisas acadêmicas falsas, minando a literatura na qual todos, de médicos a engenheiros, confiam para tomar decisões sobre vidas humanas.
Mesmo quando os artigos falsos são descobertos — geralmente por detetives amadores em seu próprio tempo — os periódicos acadêmicos geralmente demoram a retiraros artigos, permitindo que eles manchem o que muitos consideram sacrossanto: a vasta biblioteca global de trabalhos acadêmicos que apresentam novas ideias, analisam outras pesquisas e discutem descobertas.
Esses artigos falsos estão atrasando a pesquisa que ajudou milhões de pessoas com medicamentos e terapias que salvam vidas, do câncer à COVID-19. Dados de analistas mostram que campos relacionados ao câncer e à medicina são particularmente atingidos, enquanto áreas como filosofia e arte são menos afetadas. Alguns cientistas abandonaram o trabalho de suas vidas porque não conseguem acompanhar o ritmo, dada a quantidade de artigos falsos que precisam rebater.
O problema reflete uma mercantilização mundial da ciência. As universidades e seus financiadores de pesquisa há muito usam a publicação regular em periódicos acadêmicos como requisitos para promoções e segurança no emprego, gerando o mantra “publique ou pereça”.
Mas agora, fraudadores se infiltraram na indústria de publicação acadêmica para priorizar lucros em vez de bolsas de estudo. Equipados com proezas tecnológicas, agilidade e vastas redes de pesquisadores corruptos, eles estão produzindo artigos sobre tudo, desdegenes obscurosaté inteligência artificial na medicina .
Esses artigos são absorvidos pela biblioteca mundial de pesquisa mais rápido do que podem ser eliminados. Cerca de 119.000 artigos de periódicos acadêmicos e artigos de conferências são publicados globalmente a cada semana, ou mais de 6 milhões por ano.Os editores estimamque, na maioria dos periódicos, cerca de 2% dos artigos submetidos — mas não necessariamente publicados — são provavelmente falsos, embora esse número possa ser muito maior em algumas publicações.
Embora nenhum país seja imune a essa prática, ela é particularmente pronunciada em economias emergentes onde os recursos para fazer ciência genuína são limitados – e onde os governos, ansiosos para competir em escala global, promovem incentivos particularmente fortes de “publicar ou perecer”.
Como resultado, há uma movimentada economia subterrânea online para todas as coisas de publicação acadêmica. Autoria, citações, até mesmoeditores de periódicos acadêmicos, estão à venda. Essa fraude é tão prevalente que tem seu próprio nome: fábricas de papel, uma frase que remonta a “term-paper mills”, onde os alunos trapaceiam fazendo com que outra pessoa escreva um trabalho de classe para eles.
O impacto sobre os editores é profundo. Em casos de alto perfil, artigos falsos podemprejudicar os resultados financeiros de um periódico . Índices científicos importantes – bancos de dados de publicações acadêmicas nos quais muitos pesquisadores confiam para fazer seu trabalho – podemremover periódicos que publicam muitos artigos comprometidos . Há uma crítica crescente de que editores legítimos poderiam fazer mais para rastrear e colocar na lista negra periódicos e autores que publicam regularmente artigos falsos que às vezes são pouco mais do que frases geradas por inteligência artificialencadeadas .
Para entender melhor o escopo, as ramificações e as possíveis soluções desse ataque metastático à ciência, nós — um editor colaborador doRetraction Watch , um site que relata retratações de artigos científicos e tópicos relacionados, e dois cientistas da computação da Université Toulouse III–Paul Sabatier e da Université Grenoble Alpes , na França, especializados em detectar publicações falsas — passamos seis meses investigando fábricas de papel.
Isso incluiu, por alguns de nós em diferentes momentos, vasculhar sites e postagens de mídia social, entrevistar editores, especialistas em integridade de pesquisa, cientistas, médicos, sociólogos e detetives científicos envolvidos na tarefa sisífica de limpar a literatura. Também envolveu, por alguns de nós, a triagem de artigos científicos em busca de sinais de falsificação.
O que surgiu é uma crise profunda que fez com que muitos pesquisadores e formuladores de políticas clamassem por uma nova maneira para as universidades e muitos governos avaliarem e recompensarem acadêmicos e profissionais de saúde em todo o mundo.
Assim como sites altamente tendenciosos, disfarçados para parecerem reportagens objetivas, estão corroendo o jornalismo baseado em evidências eameaçando eleições , a ciência falsa está destruindo a base de conhecimento na qual a sociedade moderna se baseia.
Como parte do nosso trabalho de detecção dessas publicações falsas, o coautor Guillaume Cabanac desenvolveu o Problematic Paper Screener, quefiltra 130 milhões de artigos acadêmicos novos e antigos toda semana, procurando pornove tipos de pistasde que um artigo pode ser falso ou conter erros. Uma pista-chave é uma frase torturada – uma formulação estranha gerada por software que substitui termos científicos comuns por sinônimos para evitar plágio direto de um artigo legítimo.
Frank Cackowski, da Universidade Estadual Wayne de Detroit, ficou confuso.
O oncologista estava estudando uma sequência de reações químicas em células para ver se elas poderiam ser um alvo para medicamentos contra o câncer de próstata. Umartigo de 2018no American Journal of Cancer Research despertou seu interesse quando ele leu que uma molécula pouco conhecida chamada SNHG1 poderia interagir com as reações químicas que ele estava explorando. Ele e seu colega pesquisador da Wayne State,Steven Zielske,começaram uma série de experimentos para aprender mais sobre a ligação. Surpreendentemente, eles descobriram que não havia uma ligação.
Enquanto isso, Zielske começou a suspeitar do artigo. Dois gráficos mostrando resultados para diferentes linhas celulares eram idênticos, ele notou, o que “seria como despejar água em dois copos com os olhos fechados e os níveis saindo exatamente os mesmos”. Outro gráfico e uma tabela no artigo também continham inexplicavelmente dados idênticos.
Zielske descreveusuas dúvidasem uma postagem anônima em 2020 noPubPeer , um fórum online onde muitos cientistas relatam potenciais más condutas em pesquisas, e também contatou o editor do periódico. Pouco depois, o periódico retirou o artigo, citando “materiais e/ou dados falsificados”.
“A ciência já é difícil o suficiente se as pessoas estão realmente sendo genuínas e tentando fazer um trabalho real”, diz Cackowski, que também trabalha no Karmanos Cancer Institute em Michigan. “E é realmente frustrante desperdiçar seu tempo com base nas publicações fraudulentas de alguém.”
Os cientistas Frank Cackowski e Steven Zielske, da Wayne State, realizaram experimentos baseados em um artigo que mais tarde descobriram conter dados falsos. Amy Sacka , CC BY-ND
Ele se preocupa que as publicações falsas estejam retardando “pesquisas legítimas que, no futuro, impactarão o atendimento ao paciente e o desenvolvimento de medicamentos”.
Os dois pesquisadores finalmente descobriram que o SNHG1 parecia desempenharum papel no câncer de próstata, embora não da maneira que o artigo suspeito sugeria. Mas era um tópico difícil de estudar. Zielske vasculhou todos os estudos sobre SNHG1 e câncer — cerca de 150 artigos, quase todos de hospitais chineses — e concluiu que “a maioria” deles parecia falsa. Alguns relataram o uso de reagentes experimentais conhecidos como primers que eram “apenas rabiscos”, por exemplo, ou tinham como alvo um gene diferente do que o estudo dizia, de acordo com Zielske. Ele contatou vários periódicos, disse ele, mas recebeu pouca resposta. “Eu simplesmente parei de acompanhar.”
Os muitos artigos questionáveis também dificultaram a obtenção de financiamento, disse Zielske. A primeira vez que ele enviou uma solicitação de bolsa para estudar SNHG1, ela foi rejeitada, com um revisor dizendo que “o campo estava lotado”, Zielske lembrou. No ano seguinte, ele explicou em sua solicitação como a maior parte da literatura provavelmente veio de fábricas de papel. Ele conseguiu a bolsa.
Hoje, disse Zielske, ele aborda novas pesquisas de forma diferente do que costumava: “Você não pode simplesmente ler um resumo e ter fé nele. Eu meio que presumo que tudo está errado.”
Periódicos acadêmicos legítimos avaliam artigos antes de serem publicados, fazendo com que outros pesquisadores da área os leiam cuidadosamente. Esse processo de revisão por pares é projetado para impedir que pesquisas falhas sejam disseminadas, mas está longe de ser perfeito.
Os revisores oferecem seu tempo como voluntários, geralmente assumem que a pesquisa é real e, portanto, não procuram sinais de fraude. E alguns editores podem tentarescolher revisores que considerem mais propensos a aceitar artigos , porque rejeitar um manuscrito pode significar perder milhares de dólares em taxas de publicação.
“Até mesmo bons e honestos revisores se tornaram apáticos” por causa do “volume de pesquisa ruim que passa pelo sistema”, disse Adam Day, que dirige a Clear Skies, uma empresa em Londres que desenvolve métodos baseados em dados para ajudar a identificar artigos e periódicos acadêmicos falsificados. “Qualquer editor pode contar ter visto relatórios onde é óbvio que o revisor não leu o artigo.”
Com a IA, eles não precisam fazer isso: uma nova pesquisamostra que muitas avaliações agora são escritas pelo ChatGPT e ferramentas semelhantes.
María de los Ángeles Oviedo-García, professora de marketing na Universidade de Sevilha, na Espanha, passa seu tempo livre caçando revisões por pares suspeitas de todas as áreas da ciência, centenas das quaisela sinalizou no PubPeer. Algumas dessas revisões têm o tamanho de um tuíte, outras pedem aos autores que citem o trabalho do revisor, mesmo que não tenha nada a ver com a ciência em questão, e muitas se assemelham muito a outras revisões por pares para estudos muito diferentes — evidência, aos olhos dela, do que ela chama de “fábricas de revisão”.
Comentário do PubPeer de María de los Ángeles Oviedo-García apontando que um relatório de revisão por pares é muito semelhante a dois outros relatórios. Ela também aponta que os autores e citações para todos os três são anônimos ou a mesma pessoa – ambas as marcas registradas de artigos falsos. Captura de tela por The Conversation , CC BY-ND
“Uma das lutas mais exigentes para mim é manter a fé na ciência”, diz Oviedo-García, que diz a seus alunos para procurar artigos no PubPeer antes de confiar muito neles. Sua pesquisa foi desacelerada, ela acrescenta, porque agora ela se sente compelida a procurar relatórios de revisão por pares para estudos que ela usa em seu trabalho. Muitas vezes não há nenhum, porque “muito poucos periódicos publicam esses relatórios de revisão”, diz Oviedo-García.
Um problema ‘absolutamente enorme’
Não está claro quando as fábricas de papel começaram a operar em escala. O primeiro artigo retratado devido à suspeita de envolvimento de tais agências foi publicado em 2004, de acordo com o Retraction Watch Database , que contém detalhes sobre dezenas de milhares de retratações. (O banco de dados é operado pelo The Center for Scientific Integrity, a organização sem fins lucrativos controladora do Retraction Watch.) Também não está claro exatamente quantos artigos de baixa qualidade, plagiados ou inventados as fábricas de papel geraram.
Uma análise de 53.000 artigos submetidos a seis editoras — mas não necessariamente publicados — descobriu que a proporção de artigos suspeitos variou de 2% a 46% entre os periódicos. E a editora americana Wiley, que retiroumais de 11.300 artigos comprometidose fechou 19 periódicos fortemente afetados em sua antiga divisão Hindawi, disse recentemente que sua nova ferramenta de detecção de fábrica de papel sinalizaaté 1 em 7 submissões.
Anúncio do Facebook de uma fábrica de papel indiana vendendo coautoria de um artigo. Captura de tela por The Conversation
Day, da Clear Skies, estima que até2%dos vários milhões de trabalhos científicos publicados em 2022 foram moídos. Alguns campos são mais problemáticos do que outros. O número está mais próximo de 3% em biologia e medicina, e em alguns subcampos, como câncer, pode ser muito maior, de acordo com Day. Apesar da conscientização crescente hoje, “não vejo nenhuma mudança significativa na tendência”, disse ele. Com métodos aprimorados de detecção, “qualquer estimativa que eu fizer agora será maior”.
O problema das fábricas de papel é “absolutamente enorme”, disseSabina Alam, diretora de Ética e Integridade de Publicações na Taylor & Francis, uma grande editora acadêmica. Em 2019, nenhum dos 175 casos de ética que os editores escalaram para sua equipe era sobre fábricas de papel, disse Alam. Os casos de ética incluem submissões e artigos já publicados. Em 2023, “tivemos quase 4.000 casos”, disse ela. “E metade deles eram fábricas de papel.”
Jennifer Byrne, uma cientista australiana que agora lideraum grupo de pesquisa para melhorar a confiabilidade da pesquisa médica, apresentoudepoimento para uma audiência do Comitê de Ciência, Espaço e Tecnologia da Câmara dos Representantes dos EUA em julho de 2022. Ela observou que 700, ou quase 6%, de 12.000 artigos de pesquisa sobre câncer examinados tinham erros que poderiam indicar envolvimento de uma fábrica de papel. Byrne fechou seu laboratório de pesquisa sobre câncer em 2017porque os genes sobre os quais ela passou duas décadas pesquisando e escrevendo se tornaram alvo de um número enorme de artigos falsos. Um cientista desonesto falsificando dados é uma coisa, ela disse, mas uma fábrica de papel poderia produzir dezenas de estudos falsos no tempo que sua equipe levou para publicar um único legítimo.
“A ameaça das fábricas de papel à publicação científica e à integridade não tem paralelo em minha carreira científica de 30 anos… Somente no campo da ciência genética humana, o número de artigos potencialmente fraudulentos pode exceder 100.000 artigos originais”, ela escreveu aos legisladores, acrescentando: “Essa estimativa pode parecer chocante, mas provavelmente é conservadora.”
Em uma área da pesquisa genética – o estudo do RNA não codificador em diferentes tipos de câncer – “Estamos falando de mais de 50% dos artigos publicados são de moinhos”, disse Byrne. “É como nadar em lixo.”
Quando retratações acontecem, geralmente é graças aos esforços de uma pequena comunidade internacional de detetives amadores como Oviedo-García e aqueles que postam no PubPeer.
Jillian Goldfarb, professora associada de engenharia química e biomolecular na Universidade Cornell e ex-editora do periódico Fuel, da Elsevier, lamenta a forma como a editora lidou com a ameaça das fábricas de papel.
“Eu estava avaliando mais de 50 artigos todos os dias”, ela disse em uma entrevista por e-mail. Embora ela tivesse tecnologia para detectar plágio, envios duplicados e alterações suspeitas de autores, não era o suficiente. “Não é razoável pensar que um editor — para quem esse não é geralmente seu trabalho de tempo integral — pode pegar essas coisas lendo 50 artigos por vez. A falta de tempo, mais a pressão dos editores para aumentar as taxas de envio e citações e diminuir o tempo de revisão, coloca os editores em uma situação impossível.”
Em outubro de 2023, Goldfarb renunciou ao cargo de editora da Fuel.Em uma publicação no LinkedInsobre sua decisão, ela citou a falha da empresa em dar andamento a dezenas de artigos potenciais de fábricas de papel que ela havia sinalizado; sua contratação de um editor principal que supostamente “se envolveu em moinhos de papel e citações”; e sua proposta de candidatos para cargos editoriais “com perfis PubPeer mais longos e mais retratações do que a maioria das pessoas tem artigos em seus currículos, e cujos nomes aparecem como autores em sites de artigos para venda”.
“Isso me diz, à nossa comunidade e ao público, que eles valorizam mais a quantidade de artigos e o lucro do que a ciência”, escreveu Goldfarb.
Em resposta a perguntas sobre a renúncia de Goldfarb, um porta-voz da Elsevier disse ao The Conversation que ela “leva todas as alegações sobre má conduta em pesquisa em nossos periódicos muito a sério” e está investigando as alegações de Goldfarb. O porta-voz acrescentou que a equipe editorial da Fuel tem “trabalhado para fazer outras mudanças no periódico para beneficiar autores e leitores”.
Não é assim que funciona, amigo
Propostas de negócios acumulavam-se há anos na caixa de entrada de João de Deus Barreto Segundo, editor-chefe de seis periódicos publicados pela Escola Bahiana de Medicina e Saúde Pública em Salvador, Brasil. Várias vinham de editoras suspeitas em busca de novos periódicos para adicionar aos seus portfólios. Outras vinham de acadêmicos sugerindo acordos duvidosos ou oferecendo propinas para publicar seus artigos.
Em um e-mail de fevereiro de 2024, um professor assistente de economia na Polônia explicou que ele dirigia uma empresa que trabalhava com universidades europeias. “Você estaria interessado em colaborar na publicação de artigos científicos por cientistas que colaboram comigo?”, perguntou Artur Borcuch . “Então discutiremos possíveis detalhes e condições financeiras.”
Um administrador universitário no Iraque foi mais franco: “Como incentivo, estou preparado paraoferecer uma bolsa de US$ 500para cada artigo aceito e submetido ao seu estimado periódico”, escreveu Ahmed Alkhayyat , chefe do Centro Universitário Islâmico de Pesquisa Científica, em Najaf, e gerente do “ranking mundial” da escola.
“Não é assim que funciona, amigo”, retrucou Barreto Segundo.
Em e-mail para The Conversation, Borcuch negou qualquer intenção imprópria. “Meu papel é mediar os aspectos técnicos e processuais da publicação de um artigo”, disse Borcuch, acrescentando que, ao trabalhar com vários cientistas, ele “solicitaria um desconto do escritório editorial em nome deles”. Informado de que a editora brasileira não tinha taxas de publicação, Borcuch disse que um “erro” ocorreu porque um “funcionário” enviou o e-mail para ele “para diferentes periódicos”.
Os periódicos acadêmicos têm diferentes modelos de pagamento. Muitos são baseados em assinatura e não cobram dos autores pela publicação, mas têm taxas pesadas para a leitura de artigos. Bibliotecas e universidades também pagam grandes somas pelo acesso.
Um modelo de acesso aberto de rápido crescimento – onde qualquer um pode ler o artigo – inclui taxas de publicação caras cobradas dos autores para compensar a perda de receita na venda dos artigos. Esses pagamentos não têm a intenção de influenciar se um manuscrito é aceito ou não.
A Faculdade Bahiana de Medicina e Saúde Pública, entre outras, não cobra dos autores ou leitores, mas o empregador de Barreto Segundo é um pequeno player no negócio de publicação acadêmica, que arrecadaperto de US$ 30 bilhõespor ano commargens de lucro de até 40% . Editoras acadêmicas ganham dinheiro principalmente com taxas de assinatura de instituições como bibliotecas e universidades, pagamentos individuais para acessar artigos com paywall e taxas de acesso aberto pagas por autores para garantir que seus artigos sejam gratuitos para qualquer um ler.
A indústria élucrativao suficiente para atrair atores inescrupulosos, ansiosos por encontrar uma maneira de desviar parte dessa receita.
Ahmed Torad , um palestrante da Universidade Kafr El Sheikh no Egito e editor-chefe do Egyptian Journal of Physiotherapy , pediu um retorno de 30% para cada artigo que ele repassasse à editora brasileira. “Essa comissãoserá calculadacom base nas taxas de publicação geradas pelos manuscritos que eu enviar”, escreveu Torad, observando que ele se especializou “em conectar pesquisadores e autores com periódicos adequados para publicação”.
Trecho do e-mail de Ahmed Torad sugerindo um suborno. Captura de tela por The Conversation , CC BY-ND
Aparentemente, ele não percebeu que a Faculdade Bahiana de Medicina e Saúde Pública não cobra taxas de autoria.
Assim como Borcuch, Alkhayyat negou qualquer intenção imprópria. Ele disse que houve um “mal-entendido” por parte do editor, explicando que o pagamento que ele ofereceu era para cobrir supostas taxas de processamento de artigos. “Alguns periódicos pedem dinheiro. Então isso é normal”, disse Alkhayyat.
Torad explicou que havia enviado sua oferta de artigos de origem em troca de uma comissão para cerca de 280 periódicos, mas não havia forçado ninguém a aceitar os manuscritos. Alguns haviam se recusado a aceitar sua proposta, ele disse, apesar de cobrar regularmente milhares de dólares dos autores para publicar. Ele sugeriu que a comunidade científica não se sentia confortável em admitir que a publicação acadêmica se tornou um negócio como qualquer outro, mesmo que seja “óbvio para muitos cientistas”.
Os avanços indesejados tiveram como alvo um dos periódicos administrados por Barreto Segundo, o Journal of Physiotherapy Research, logo após ele ter sido indexado no Scopus, um banco de dados de resumos e citações de propriedade da editora Elsevier.
Junto com o Web of Science da Clarivate, o Scopus se tornou um importante selo de qualidade para publicações acadêmicas globalmente. Artigos em periódicos indexados são dinheiro no banco para seus autores: eles ajudam a garantir empregos, promoções, financiamento e, em alguns países, até mesmo acionar recompensas em dinheiro. Para acadêmicos ou médicos em países mais pobres, eles podem seruma passagem para o norte global .
Considere o Egito, um paísatormentado por ensaios clínicos duvidosos . As universidades de lá geralmente pagam grandes somas aos funcionários por publicações internacionais, com ovalor dependendo do fator de impacto do periódico. Uma estrutura de incentivo semelhante está embutida em regulamentações nacionais: para ganhar o posto de professor titular, por exemplo, os candidatos devem ter pelo menos cinco publicaçõesem dois anos, de acordo com o Conselho Supremo de Universidades do Egito. Estudos em periódicos indexados no Scopus ou Web of Science não apenas recebem pontos extras, mas também são isentos de um exame mais aprofundado quando os candidatos são avaliados. Quanto maior o fator de impacto de uma publicação, mais pontos os estudos recebem.
Com tanto foco em métricas, tornou-se comum para pesquisadores egípcios cortarem custos, de acordo com um médico no Cairo que pediu anonimato por medo de retaliação. A autoria é frequentemente presenteada a colegas que depois retribuem o favor, ou estudos podem ser criados do nada. Às vezes, um artigo legítimo existente é escolhido da literatura, e detalhes importantes como o tipo de doença ou cirurgia são então alterados e os números ligeiramente modificados, explicou a fonte.
Isso afeta as diretrizes clínicas e os cuidados médicos, “então é uma pena”, disse o médico.
A ivermectina, um medicamento usado para tratar parasitas em animais e humanos, é um exemplo. Quando alguns estudos mostraram que era eficaz contra a COVID-19, a ivermectina foi aclamada como uma “droga milagrosa”no início da pandemia. As prescrições aumentaram e, junto com elas,as ligações para os centros de controle de intoxicações dos EUA; um homem passou nove dias no hospital após tomar uma formulação injetável do medicamento que era destinada ao gado, de acordo com os Centros de Controle e Prevenção de Doenças. Como se viu, quase todas as pesquisas que mostraram um efeito positivo na COVID-19 tinham indícios de falsificação, a BBC e outros relataram – incluindoum estudo egípcio agora retirado . Sem nenhum benefício aparente , os pacientes ficaram apenas com efeitos colaterais.
“Há um enorme incentivo acadêmico e motivo de lucro”, diz Lisa Bero, professora de medicina e saúde pública no Campus Médico Anschutz da Universidade do Colorado e editora sênior de integridade de pesquisa na Cochrane Collaboration, uma organização internacional sem fins lucrativos que produz revisões de evidências sobre tratamentos médicos. “Vejo isso em todas as instituições em que trabalhei.”
Mas no sul global, o decreto de publicar ou perecer esbarra em infraestruturas de pesquisa e sistemas educacionais subdesenvolvidos, deixando os cientistas em apuros. Para um Ph.D., o médico do Cairo que pediu anonimato conduziu um ensaio clínico inteiro sozinho – desde a compra do medicamento do estudo até a randomização de pacientes, coleta e análise de dados e pagamento de taxas de processamento de artigos. Em nações mais ricas, equipes inteiras trabalham em tais estudos, com a conta facilmente chegando a centenas de milhares de dólares.
“A pesquisa é bem desafiadora aqui”, disse o médico. É por isso que os cientistas “tentam manipular e encontrar maneiras mais fáceis para que eles façam o trabalho.”
As instituições também manipularam o sistema com um olho nas classificações internacionais. Em 2011, a revista Science descreveu como pesquisadores prolíficos nos Estados Unidos e na Europa receberam ofertas de pagamentos pesados para listar universidades sauditas como afiliações secundárias em artigos. E em 2023, a revista, em colaboração com a Retraction Watch, descobriu um estratagema massivo de autocitação por uma escola de odontologia de primeira linha na Índia que forçou alunos de graduação a publicar artigos referenciando trabalhos do corpo docente.
A raiz – e as soluções
Esses esquemas desagradáveis podem ser rastreados até a introdução de métricas baseadas em desempenho na academia, um desenvolvimento impulsionado pelo movimento New Public Managementque varreu o mundo ocidental na década de 1980, de acordo com o sociólogo canadense da ciência Yves Gingras, da Université du Québec à Montréal. Quando universidades e instituições públicas adotaram a gestão corporativa, os artigos científicos se tornaram “unidades contábeis” usadas para avaliar e recompensar a produtividade científica em vez de “unidades de conhecimento” que avançam nossa percepção do mundo ao nosso redor,escreveu Gingras .
Essa transformação levou muitos pesquisadores a competir em números em vez de conteúdo, o que tornou as métricas de publicaçãomedidas ruinsde proeza acadêmica. Como Gingras mostrou, o controverso microbiologista francês Didier Raoult, que agora temmais de uma dúzia deretratações em seu nome, tem um índice h – uma medida que combina números de publicação e citação – que éduas vezes maiorque o de Albert Einstein – “prova de que o índice é absurdo”, disse Gingras.
Pior, uma espécie de inflação científica, ou “ bolha cienciométrica”, ocorreu, com cada nova publicação representando um incremento cada vez menor no conhecimento. “Publicamos cada vez mais artigos superficiais, publicamos artigos que precisam ser corrigidos e pressionamos as pessoas a cometer fraudes”, disse Gingras.
Em 2024, Landon Halloran, um geocientista da Universidade de Neuchâtel, na Suíça, recebeu uma candidatura incomum para uma vaga em seu laboratório. Um pesquisador com doutorado da China havia enviado seu currículo. Aos 31 anos, o candidato havia acumulado 160 publicações em periódicos indexados pela Scopus, 62 delas somente em 2022, o mesmo ano em que obteve seu doutorado. Embora o candidato não fosse o único “com uma produção suspeitamente alta”, de acordo com Halloran, ele se destacou. “Meus colegas e eu nunca encontramos nada parecido nas geociências”, disse ele.
De acordo com insiders e editores da indústria, há mais conscientização agora sobre ameaças de fábricas de papel e outros atores ruins. Alguns periódicos verificam rotineiramente se há fraude de imagem. Uma imagem ruim gerada por IA aparecendo em um artigo pode ser um sinal de um cientista tomando um atalho mal aconselhado, ou de uma fábrica de papel.
A Cochrane Collaboration temuma políticaque exclui estudos suspeitos de suas análises de evidências médicas. A organização também vem desenvolvendo uma ferramentapara ajudar seus revisores a identificar ensaios médicos problemáticos, assim como os editores começaram a selecionar submissões ecompartilhar dados e tecnologiasentre si para combater fraudes.
Esta imagem, gerada por IA, é um jargão visual de conceitos sobre transporte e administração de medicamentos no corpo. Por exemplo, a figura superior esquerda é uma mistura sem sentido de uma seringa, um inalador e pílulas. E a molécula transportadora sensível ao pH na parte inferior esquerda é enorme, rivalizando com o tamanho dos pulmões. Depois que cientistas detetives apontaram que a imagem publicada não fazia sentido, o periódico emitiu uma correção. Captura de tela por The Conversation , CC BY-ND
Este gráfico é a imagem corrigida que substituiu a imagem de IA acima. Neste caso, de acordo com a correção, o periódico determinou que o artigo era legítimo, mas os cientistas usaram IA para gerar a imagem que o descrevia. Captura de tela por The Conversation , CC BY-ND
“As pessoas estão percebendo, tipo, uau, isso está acontecendo na minha área, está acontecendo na sua área”, disse Bero, da Cochrane Collaboration. “Então, realmente precisamos nos coordenar e, você sabe, desenvolver um método e um plano geral para acabar com essas coisas.”
O que fez a Taylor & Francis prestar atenção, de acordo com Alam, o diretor de Ética e Integridade de Publicações, foi umainvestigação de 2020 de uma fábrica de papel chinesa pela detetive Elisabeth Bik e três de seus colegas que atendem pelos pseudônimos Smut Clyde, Morty e Tiger BB8. Com 76 artigos comprometidos, a Artificial Cells, Nanomedicine, and Biotechnology da empresa sediada no Reino Unido foi o periódico mais afetado identificado na investigação.
“Isso abriu um campo minado”, diz Alam, que também copresideo United2Act, um projeto lançado em 2023 que reúne editores, pesquisadores e detetives na luta contra as fábricas de papel. “Foi a primeira vez que percebemos que as imagens de stock estavam sendo usadas essencialmente para representar experimentos.”
A Taylor & Francis decidiu auditar as centenas de artigos em seu portfólio que continham tipos semelhantes de imagens. Ela dobrou a equipe da Alam, que agora tem 14,5 posições dedicadas a fazer investigações, e também começou a monitorar as taxas de envio. As fábricas de papel, ao que parecia, não eram clientes exigentes.
“O que eles estão tentando fazer é encontrar um portão e, se conseguirem entrar, eles simplesmente começam a bater nas submissões”, disse Alam. Setenta e seis artigos falsos de repente pareciam uma gota no oceano. Em um periódico da Taylor & Francis, por exemplo, a equipe de Alam identificou quase 1.000 manuscritos que traziam todas as marcas de terem vindo de uma fábrica, disse ela.
E em 2023, rejeitou cerca de 300 propostas duvidosas para edições especiais. “Nós bloqueamos um monte de coisas de passarem”, disse Alam.
Verificadores de fraude
Uma pequena indústria de startups de tecnologia surgiu para ajudar editores, pesquisadores e instituições a identificar potenciais fraudes. O siteArgos, lançado em setembro de 2024 pela Scitility , um serviço de alerta sediado em Sparks, Nevada, permite que autores verifiquem se novos colaboradores são rastreados por retratações ou preocupações com má conduta. Ele sinalizou dezenas de milhares de artigos de “alto risco” , de acordo com o periódico Nature.
Ferramentas de verificação de fraudes examinam documentos para apontar aqueles que devem ser verificados manualmente e possivelmente rejeitados. solidcolours/iStock via Getty Images
Os fraudadores também não ficaram parados. Em 2022, quando a Clear Skies lançou o Papermill Alarm, o primeiro acadêmico a perguntar sobre a nova ferramenta foi um moinho de papel, de acordo com Day. A pessoa queria acesso para poder verificar seus artigos antes de enviá-los para as editoras, disse Day. “As fábricas de papel provaram ser adaptáveis e também bastante rápidas no início.”
Dada a atual corrida armamentista, Alam reconhece que a luta contra as fábricas de papel não será vencida enquanto a crescente demanda por seus produtos permanecer.
De acordo com umaanálise da Nature , a taxa de retração triplicou de 2012 a 2022 para perto de 0,02%, ou cerca de 1 em 5.000 artigos. Então, quase dobrou em 2023, em grande parte por causa dodesastre Hindawi da Wiley . A publicação comercial de hoje é parte do problema, disse Byrne. Por um lado, limpar a literatura é um empreendimento vasto e caro, sem nenhuma vantagem financeira direta. “Jornais e editoras nunca serão capazes, no momento, de corrigir a literatura na escala e na pontualidade necessárias para resolver o problema da fábrica de papel”, disse Byrne. “Ou temos que monetizar as correções de forma que as editoras sejam pagas por seu trabalho, ou esquecer as editoras e fazer isso nós mesmos.”
Mas isso ainda não consertaria o viés fundamental embutido na publicação com fins lucrativos: os periódicos não são pagos para rejeitar artigos. “Nós os pagamos para aceitar artigos”, disse Bodo Stern, ex-editor do periódico Cell e chefe de Iniciativas Estratégicas do Howard Hughes Medical Institute, uma organização de pesquisa sem fins lucrativos e grande financiadora em Chevy Chase, Maryland. “Quero dizer, o que você acha que os periódicos vão fazer? Eles vão aceitar artigos.”
Commais de 50.000 periódicosno mercado, mesmo que alguns estejam se esforçando para acertar, artigos ruins que são vendidos por tempo suficiente eventualmente encontram um lar, Stern acrescentou. “Esse sistema não pode funcionar como um mecanismo de controle de qualidade”, disse ele. “Temos tantos periódicos que tudo pode ser publicado.”
Na visão de Stern, o caminho a seguir é parar de pagar periódicos para aceitar artigos e começar a vê-los como serviços públicos que atendem a um bem maior. “Devemos pagar por mecanismos de controle de qualidade transparentes e rigorosos”, disse ele.
A revisão por pares, enquanto isso, “deve ser reconhecida como um verdadeiro produto acadêmico, assim como o artigo original, porque os autores do artigo e os revisores por pares estão usando as mesmas habilidades”, disse Stern. Da mesma forma, os periódicos devem tornar todos os relatórios de revisão por pares publicamente disponíveis, mesmo para manuscritos que eles rejeitam. “Quando eles fazem o controle de qualidade, eles não podem simplesmente rejeitar o artigo e então deixá-lo ser publicado em outro lugar”, disse Stern. “Esse não é um bom serviço.”
Melhores medidas
Stern não é o primeiro cientista a lamentar o foco excessivo na bibliometria. “Precisamos de menos pesquisa, melhor pesquisa e pesquisa feita pelos motivos certos”, escreveu o falecido estatístico Douglas G. Altman em umeditorial muito citado de 1994. “Abandonar o uso do número de publicações como uma medida de habilidade seria um começo.”
Apesar da declaração, as métricas continuam sendo amplamente utilizadas hoje, e os cientistas dizem que há um novo senso de urgência.
“Estamos chegando ao ponto em que as pessoas realmente sentem que precisam fazer alguma coisa” por causa do grande número de artigos falsos, disse Richard Sever, diretor assistente da Cold Spring Harbor Laboratory Press, em Nova York, e cofundador dos servidores de pré-impressão bioRxiv e medRxiv.
Stern e seus colegas tentaram fazer melhorias em sua instituição. Pesquisadores que desejam renovar seus contratos de sete anos há muito tempo são obrigados a escrever um pequeno parágrafo descrevendo a importância de seus principais resultados. Desde o final de 2023, eles também são solicitados a remover nomes de periódicos de suas inscrições.
Dessa forma, “você nunca pode fazer o que todos os revisores fazem – eu já fiz – olhar a bibliografia e em apenas um segundo decidir, ‘Oh, essa pessoa foi produtiva porque publicou muitos artigos e eles foram publicados nos periódicos certos’”, diz Stern. “O que importa é: isso realmente fez a diferença?”
Mudar o foco de métricas de desempenho convenientes parece possível não apenas para instituições privadas ricas como o Howard Hughes Medical Institute, mas também para grandes financiadores governamentais. Na Austrália, por exemplo, o National Health and Medical Research Council lançou em 2022 a política “top 10 em 10 ”, visando, em parte, “valorizar a qualidade da pesquisa em vez da quantidade de publicações”.
Em vez de fornecer sua bibliografia completa, a agência, que avalia milhares de solicitações de subsídios todos os anos, pediu aos pesquisadores que listassem no máximo 10 publicações da última década e explicassem a contribuição que cada uma delas havia feito para a ciência. De acordo com umrelatório de avaliaçãode abril de 2024, quase três quartos dos revisores de subsídios disseram que a nova política permitiu que eles se concentrassem mais na qualidade da pesquisa do que na quantidade. E mais da metade disse que ela reduziu o tempo gasto em cada solicitação.
Gingras, o sociólogo canadense, defende dar aos cientistas o tempo de que precisam para produzir um trabalho que importe, em vez de um fluxo jorrando de publicações. Ele é signatário do Slow Science Manifesto: “Quando você obtém slow science, posso prever que o número de corrigendas, o número de retratações, diminuirá”, ele diz.
Em um ponto, Gingras estava envolvido na avaliação de uma organização de pesquisa cuja missão era melhorar a segurança no local de trabalho. Um funcionário apresentou seu trabalho. “Ele tinha uma frase que nunca esquecerei”, lembra Gingras. O funcionário começou dizendo: “’Sabe, tenho orgulho de uma coisa: meu índice h é zero.’ E foi brilhante.” O cientista havia desenvolvido uma tecnologia que prevenia quedas fatais entre trabalhadores da construção. “Ele disse: ‘Isso é útil, e esse é meu trabalho.’ Eu disse: ‘Bravo!’”
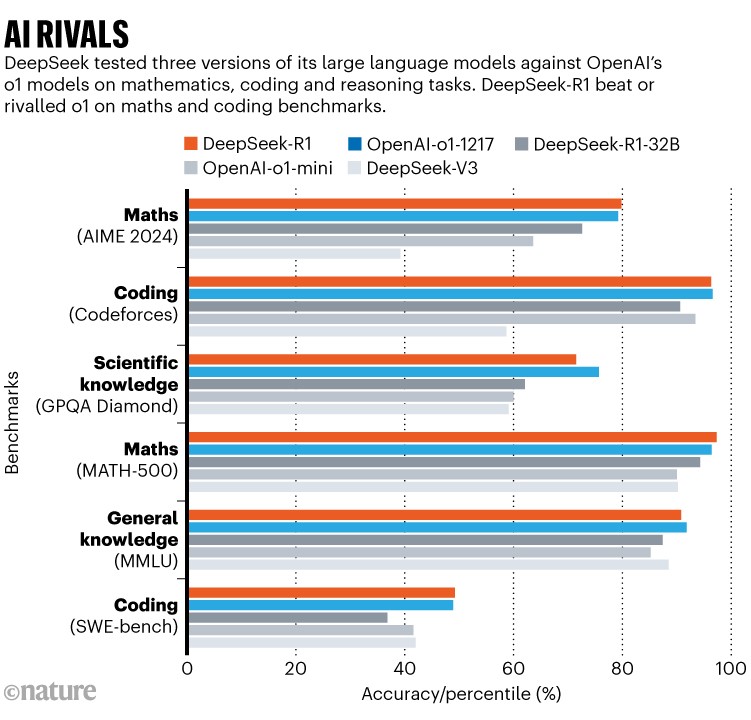
O DeepSeek-R1 executa tarefas de raciocínio no mesmo nível que o o1 da OpenAI — e está aberto para análise por pesquisadores
A empresa chinesa DeepSeek estreou uma versão de seu grande modelo de linguagem no ano passado. Crédito: Koshiro K/Alamy
Por Elizabeth Gibney para a “Nature”
Um grande modelo de linguagem desenvolvido na China, chamado DeepSeek-R1, está entusiasmando os cientistas como um rival acessível e aberto aos modelos de “raciocínio” como o o1 da OpenAI.
Esses modelos geram respostas passo a passo, em um processo análogo ao raciocínio humano. Isso os torna mais aptos do que os modelos de linguagem anteriores para resolver problemas científicos, e significa que eles podem ser úteis em pesquisas. Os testes iniciais do R1, lançado em 20 de janeiro, mostram que seu desempenho em certas tarefas em química, matemática e codificação está no mesmo nível do o1 — que impressionou os pesquisadores quando foi lançado pela OpenAI em setembro.
“Isso é selvagem e totalmente inesperado”, escreveu Elvis Saravia, pesquisador de inteligência artificial (IA) e cofundador da empresa de consultoria em IA sediada no Reino Unido, DAIR.AI, no X.
O R1 se destaca por outro motivo. A DeepSeek, a start-up em Hangzhou que construiu o modelo, o lançou como ‘open-weight’, o que significa que os pesquisadores podem estudar e construir sobre o algoritmo. Publicado sob uma licença do MIT, o modelo pode ser reutilizado livremente, mas não é considerado totalmente de código aberto, porque seus dados de treinamento não foram disponibilizados.
“A abertura do DeepSeek é bastante notável”, diz Mario Krenn, líder do Artificial Scientist Lab no Instituto Max Planck para a Ciência da Luz em Erlangen, Alemanha. Em comparação, o1 e outros modelos construídos pela OpenAI em São Francisco, Califórnia,incluindo seu último esforço, o3, são “essencialmente caixas-pretas”, ele diz.
O DeepSeek não divulgou o custo total do treinamento do R1, mas está cobrando das pessoas que usam sua interface cerca de um trigésimo do que o o1 custa para executar. A empresa também criou mini versões ‘destiladas’ do R1 para permitir que pesquisadores com poder de computação limitado brinquem com o modelo. Um “experimento que custou mais de £ 300 [US$ 370] com o o1, custou menos de US$ 10 com o R1”, diz Krenn. “Esta é uma diferença dramática que certamente desempenhará um papel em sua adoção futura.”
Modelos de desafio
O R1 faz parte de umboom em modelos de linguagem chinesa (LLMs). Desmembrado de um fundo de hedge, o DeepSeek emergiu da relativa obscuridade no mês passado quando lançou um chatbot chamado V3, que superou os principais rivais, apesar de ter sido construído com um orçamento apertado. Especialistas estimam que custou cerca de US$ 6 milhões para alugar o hardware necessário para treinar o modelo, em comparação com mais de US$ 60 milhões para o Llama 3.1 405B da Meta, que usou 11 vezes os recursos de computação.
Parte do burburinho em torno do DeepSeek é que ele conseguiu fazer o R1 apesar dos controles de exportação dos EUA que limitam o acesso das empresas chinesas aos melhores chips de computador projetados para processamento de IA. “O fato de ele vir da China mostra que ser eficiente com seus recursos importa mais do que apenas a escala de computação”, diz François Chollet, um pesquisador de IA em Seattle, Washington.
O progresso do DeepSeek sugere que “a liderança percebida [que os] EUA já tiveram diminuiu significativamente”, escreveu Alvin Wang Graylin, especialista em tecnologia em Bellevue, Washington, que trabalha na empresa de tecnologia imersiva HTC, sediada em Taiwan, no X. “Os dois países precisam buscar uma abordagem colaborativa para construir IA avançada em vez de continuar com a atual abordagem de corrida armamentista sem vitória.”
Cadeia de pensamento
Os LLMs treinam em bilhões de amostras de texto, cortando-as em partes de palavras, chamadas tokens, e padrões de aprendizagem nos dados. Essas associações permitem que o modelo preveja tokens subsequentes em uma frase. Mas os LLMs são propensos a inventar fatos, um fenômeno chamado alucinação , e muitas vezes lutam para raciocinar sobre problemas.
Assim como o o1, o R1 usa um método de ‘cadeia de pensamento’ para melhorar a capacidade de um LLM de resolver tarefas mais complexas, incluindo, às vezes, retroceder e avaliar sua abordagem. O DeepSeek fez o R1 ‘ajustando’ o V3 usando aprendizado por reforço, que recompensou o modelo por chegar a uma resposta correta e por trabalhar em problemas de uma forma que delineasse seu ‘pensamento’.
Fonte: DeepSeek
Ter poder de computação limitado levou a empresa a “inovar algoritmicamente”, diz Wenda Li, pesquisadora de IA na Universidade de Edimburgo, Reino Unido. Durante o aprendizado por reforço, a equipe estimou o progresso do modelo em cada estágio, em vez de avaliá-lo usando uma rede separada. Isso ajudou a reduzir os custos de treinamento e execução, diz Mateja Jamnik, cientista da computação na Universidade de Cambridge, Reino Unido. Os pesquisadores também usaram uma arquitetura de ‘mistura de especialistas’, que permite que o modelo ative apenas as partes de si mesmo que são relevantes para cada tarefa.
Em testes de benchmark, relatados em umartigo técnicoque acompanha o modelo, o DeepSeek-R1 pontuou 97,3% no conjunto de problemas de matemática MATH-500 criado por pesquisadores da Universidade da Califórnia, Berkeley, e superou 96,3% dos participantes humanos em uma competição de programação chamada Codeforces. Isso está no mesmo nível das habilidades do o1; o o3 não foi incluído nas comparações (veja ‘IA rivais’).
É difícil dizer se os benchmarks capturam a verdadeira capacidade de um modelo de raciocinar ou generalizar, ou meramente sua proficiência em passar em tais testes. Mas como o R1 é aberto, sua cadeia de pensamento é acessível aos pesquisadores, diz Marco Dos Santos, um cientista da computação da Universidade de Cambridge. “Isso permite melhor interpretabilidade dos processos de raciocínio do modelo”, ele diz.
Os cientistas já estão testando as habilidades do R1. Krenn desafiou ambos os modelos rivais a classificar 3.000 ideias de pesquisa pelo quão interessantes elas são e comparou os resultados com classificações feitas por humanos. Nesta medida, o R1 teve um desempenho ligeiramente inferior ao do o1. Mas o R1 venceu o o1 em certos cálculos em óptica quântica, diz Krenn. “Isso é bastante impressionante.”
Por Carlos Eduardo Martins para o “Blog da Boitempo”
Quando da posse do novo presidente dos Estados Unidos, alertamos nas redes sociais que as Big Techs se aproximaram de Trump porque estavam mais fracas e buscavam proteção contra a concorrência chinesa. Mencionamos que o custo dessa aproximação era altíssimo: perda da suposta neutralidade, desgaste social e político, defesa da redução de impostos e direitos, das emissões de carbono e suspeição de vinculação ao neonazismo. A recente divulgação da produção de software de inteligência artificial pela China com performance similar e custos 10 vezes menores que os das Big Techs norte-americanas evidencia a correção de nosso argumento e a profundidade da crise do setor de alta tecnologia estadunidense, que deverá se aprofundar nos próximos anos.
A notícia dos novos chatbots da DeepSek, Deep-Seek-R1 e DeepSeek-R1-Zero, provocou a queda de 17% dos preços das ações da Niyvia em apenas um dia, arrastando para baixo todo o setor de alta tecnologia. Gerou perdas de US$ 1 trilhão nesse segmento, impactando negativamente a Nasdak e a S&P 500, entre outros ativos, como as ações de Google, Amazon, Meta e Microsoft, atingindo diretamente grande parte dos bilionários que estão se escorando em Trump.
A China provou que o bloqueio que sofre à importação de alta tecnologia é inútil para excluí-la da corrida pela fronteira tecnológica. E isso por várias razões:
a) a China investe fortemente na capacitação de sua força de trabalho e vem repatriando parte dos cientistas e engenheiros formados no exterior;
b) prioriza o desenvolvimento de software ao de hardware, vinculando-se muito mais profundamente à revolução científico-técnica, que tem como principal fundamento a qualificação e o aumento do valor da força de trabalho;
c) desenvolve softwares de código aberto, priorizando a articulação entre a socialização de forças produtivas, a criação e a diversidade, abrindo-se potencialmente para combinar a contribuição de trabalhadores de todo o mundo. Trata-se de um gigantesco processo de formação do trabalho coletivo em construção que desafia o monopólio tecnológico e coloca a potência asiática à frente do vale do Silício na disputa pela fronteira tecnológica. Para reduzir os custos da inteligência artificial, a Deep Seek utilizou não apenas programadores, mas profissionais das ciências humanas e poetas.
Esse evento não é aleatório, mas um ponto de inflexão associado ao desenvolvimento de uma nova etapa da revolução científico-técnica e às profundas modificações que ela está gerando nas condições de existência: a automação ao setor de serviços, a ampliação do trabalho intelectual — vinculado à ciência, educação, cultura e lazer —, e a transição energética para formas renováveis e limpas.
Está em curso no mundo a luta das forças do século XXI, que o querem parir, contra aquelas do século XX, que pretendem deter a marcha da história da humanidade e, se necessário, destruí-la.
De um lado, temos um paradigma emergente baseado na socialização. Ele se materializa no protagonismo do conhecimento sobre a tecnologia material, das energias renováveis sobre os combustíveis fósseis, do diálogo sobre a força, da paz sobre a guerra, e da propriedade coletiva sobre a privada. A China, hoje, responde por 80% da produção de energia renovável no mundo, e em segundo lugar está a Indonésia, que acaba se associar ao BRICS como membro pleno. Embora as energias renováveis respondam por cerca de 20% da produção de energia do mundo atualmente, a previsão é de que em 2050 possam responder pela metade.
De outro lado, está o imperialismo, o territorialismo, a intimidação, a coação e a guerra. Esse projeto traz a pretensão de retomar o Destino Manifesto em versão aditivada, estendendo o espaço vital estadunidense para todo o Hemisfério Ocidental, da Groelândia até a Terra do Fogo. Ele se baseia no controle espacial, reage contra a emergência do paradigma verde e mantém a sua aposta em uma economia mundial baseada em combustíveis fósseis, sobre os quais pretende criar monopólios, protetorados e dependências permanentes.
Este é o sentido mais profundo do dilema que está em curso no mundo atual. Senhoras e senhores, ajustem as suas teorias. Não podemos olhar os dilemas do mundo contemporâneo com visões que mirem o nosso tempo com as mesmas estruturas mentais do territorialismo e do domínio das energias fósseis sobre o planeta.
A economia política das sanções e das guerras que os Estados Unidos estão impulsionando não representam apenas ameaças. São também janelas de oportunidade para a integração regional e o desenvolvimento das conexões comerciais, produtivas, financeiras e militares entre o Sul Global. Os países latino-americanos precisam se preparar para esse cenário. Para isso, necessitam de lideranças ousadas, criativas e determinadas para romper com a austeridade neoliberal e o imperialismo estadunidense, restabelecer e aprofundar a agenda da integração regional — que foi interrompida e desmontada — e articulá-la com as forças multipolares emergentes, que têm no BRICS um eixo fundamental. O Brasil goza de condições estruturais excepcionais para atuar nesse cenário, constituindo um país anfíbio com forte vocação continental e marítima, imensa dotação de recursos naturais e minerais, membro pleno e fundador do BRICS, exercendo atualmente a sua presidência, com imensa projeção na América do Sul. Falta ajustar as suas condições subjetivas, políticas e ideológicas às suas possibilidades estruturais.
O logotipo da empresa chinesa de inteligência artificial DeepSeek é visto em Hangzhou, província de Zhejiang, China, em 26 de janeiro de 2025. CFOTO/Future Publishing via Getty Images
Por Ryan Grim e Waqas Ahmed para o DropSite
As ações de tecnologia dos EUA estão despencando enquanto a China parece estar expondo as empresas americanas envolvidas em Inteligência Artificial (IA) como extremamente supervalorizadas. É uma consequência previsível de como o governo americano abordou o Vale do Silício e vice-versa. Este não é o tipo de coisa que normalmente cobrimos, mas não confiamos muito na mídia dos EUA para contar essa história com precisão.
Qualquer um que acompanha casualmente viu como foi. Empresas de tecnologia dos EUA, com o apoio do governo federal (e do Pentágono), construíram uma posição global dominante por meio de inovação genuína. Microsoft, Facebook, Apple, Google e Amazon remodelaram o mundo. A Microsoft, uma das primeiras grandes empresas a crescer, tentou interromper essa inovação comprando e/ou esmagando seus concorrentes, mas os EUA a processaram em 1998 por violar as leis antitruste. O governo Bush resolveu o caso, recuando no esforço de separá-los. O que se seguiu foi um abraço bipartidário da Big Tech; as eras Bush e Obama viram crescimento desenfreado e fusões. À medida que as empresas de tecnologia viam empresas menores inovando, elas compravam a empresa, a matavam e absorviam parte de sua equipe.
Um movimento antimonopólio começou a borbulhar, levando a processos judiciais contra Facebook, Amazon, Google e Apple na última década. Lina Khan, como presidente da Comissão Federal de Comércio sob o ex-presidente Joe Biden, tornou-se uma heroína popular ao alertar que a ganância e a consolidação não estavam prejudicando apenas consumidores e trabalhadores, mas que as próprias empresas escleróticas acabariam sofrendo com a falta de concorrência. “Nossa história mostra que manter mercados abertos, justos e competitivos, especialmente em pontos de inflexão tecnológica, é uma maneira fundamental de garantir que a América se beneficie da inovação que essas ferramentas podem catalisar”,disse Khan em 2023.
Agora ficou claro que o fosso que os EUA construíram para proteger suas empresas da concorrência doméstica na verdade criou as condições que permitiram que elas atrofiassem. Elas ficaram gordas e felizes dentro de seus castelos. Seus negócios mudaram da inovação tecnológica para a realização de alquimia com planilhas, transformando métricas inventadas em avaliações em dólares desvinculadas da realidade. Agora, a DeepSeek expôs o golpe. Com uma pequena fração dos recursos e sem acesso a toda a panóplia de tecnologia de chips dos EUA, a empresa chinesa DeepSeek enganou o Vale do Silício. A empresa americana OpenAI começou como uma organização sem fins lucrativos dedicada a tornar a IA amplamente disponível, como seu nome sugere. Seu chefe, Sam Altman, conseguiu transformá-la em uma empresa com fins lucrativos e fechá-la.
Agora, o DeepSeek está ironicamente cumprindo a missão original do OpenAI ao fornecer um modelo de código aberto que simplesmente tem melhor desempenho do que qualquer outro no mercado.
Enquanto isso, aqui nos Estados Unidos, Trump está comemorando um investimento (possivelmente exagerado) de US$ 500 bilhões no Texas para abastecer o poder computacional de IA que parece estar obsoleto — ou muito menos relevante — graças à inovação da DeepSeek. E Trump está enchendo sua administração com manos da criptografia, magnatas da tecnologia se recusando a desinvestir e até lançou sua própria moeda meme de golpe. Os principais conselheiros de tecnologia de Trump, como Elon Musk, enquanto isso, têm extensos laços comerciais diretamente com a China. Você não precisa apertar os olhos muito para ver qual desses países vai ganhar essa competição.
O contrato social firmado entre o governo dos EUA e o Vale do Silício — do qual o povo americano se tornou parte involuntária — era direto: deixaremos um punhado de caras da tecnologia se tornarem incomensuravelmente ricos e, em troca, eles construirão uma indústria de tecnologia que manterá a América globalmente dominante. Em vez disso, os caras da tecnologia quebraram o acordo. Eles pegaram o dinheiro, mas em vez de continuar a inovar e competir, construíram monopólios para manter a concorrência fora — até mesmo recebendo a ajuda do estado de segurança nacional dos EUA para bloquear o acesso chinês à nossa tecnologia. Mas eles não conseguiram ficar fora da competição para sempre. Lina Khan estava certa. E agora aqui estamos.
Os efeitos posteriores serão profundos se a trajetória de uma transferência de riqueza dos EUA para a China continuar acelerada. É comum dizer que a maioria das pessoas não possui ações individuais, mas isso subestima a exposição que todos nós temos a esse golpe. Está em nossos IRAs ou 401ks e a ascensão dessas ações constituiu quase todo o crescimento do mercado de ações nos últimos anos. E se a China se tornar cada vez mais o lugar para trabalhar se você for um pesquisador ou desenvolvedor ambicioso, não é difícil ver aonde isso leva.
Abaixo está uma explicação sobre o DeepSeek que pedimos ao nosso correspondente Waqas Ahmed para elaborar.
CEO da OpenAI, Sam Altman. Foto de Justin Sullivan/Getty Images.
P: O que é DeepSeek e por que ele está causando um colapso nas ações?
R: A empresa chinesa DeepSeek lançou um modelo de IA que é tão bom quanto qualquer um de seus equivalentes americanos e o tornou de código aberto. Isso mudou fundamentalmente a economia e a política da indústria de IA em rápido crescimento, que até agora tem sido liderada por um oligopólio de empresas de tecnologia americanas tentando posicionar os Large Language Models (LLMs) como o avanço tecnológico definidor deste século, e eles próprios como os guardiões de seu molho secreto.
Há muita conversa sobre o DeepSeek custar apenas cerca de US$ 6 milhões para ser construído,embora esse valornão inclua pesquisa e desenvolvimento. E, apesar dos controles de exportação, o DeepSeek conseguiu explorar um número não trivial de chips de alta tecnologia que estávamos tentando manter deles. No entanto, ainda é um choque enorme para a indústria dos EUA.
P: O que são LLMs e como eles surgiram ?
R: Um artigo de 2017 intitulado “Atenção é tudo o que você precisa” foi um ponto de virada na indústria de IA. O artigo descreveu um método de criação de um modelo de aprendizado de máquina que poderia produzir texto semelhante ao humano com precisão e escala sem precedentes usando uma arquitetura chamada “transformadores”. Esses “transformadores” melhoraram consideravelmente uma classe de modelos chamados Large Language Models (LLMs). Os LLMs usam grandes quantidades de texto — livros, artigos, e-mails, receitas, perguntas frequentes, tudo — para criar representações matemáticas internas de relacionamentos entre bilhões de palavras e frases — ou, mais precisamente, entre combinações de tokens encontrados em uma linguagem humana natural.
Antes de 2017, os LLMs não eram muito úteis, mas os “transformadores” mudaram isso. Ao processar grandes quantidades de texto usando a arquitetura do transformador, esses modelos agora podiam “aprender” o que as palavras significam em diferentes contextos e detectar nuances que os computadores nunca tinham conseguido antes, permitindo que esses modelos produzissem texto extremamente relevante em resposta a um prompt ou pergunta do usuário.
P: Como começou o entusiasmo pela IA?
R: A OpenAI se tornou a primeira empresa americana a demonstrar que se você tirar um instantâneo de toda a internet conhecida e de todos os livros digitalizados existentes sem se preocupar muito com a lei de direitos autorais , você pode criar um modelo tão bom que sua saída seria quase indistinguível daquela de um burocrata de DC com inteligência medíocre. No entanto, a OpenAI mostrou que seu modelo poderia ser treinado para ter experiência em diferentes domínios e poderia dar respostas aprofundadas a perguntas muito específicas. Seu modelo passou em exames de codificação, no exame da ordem e se formou na escola de negócios. Os resultados foram tão chocantes que a OpenAI saiu e afirmou que valia um zilhão de dólares e que ofuturo da humanidadedependia disso.
P: Qual é o estado atual do setor de IA?
R: A OpenAI, parcialmente de propriedade da Microsoft, foi a primeira a lançar um grande produto LLM, o ChatGPT, em novembro de 2022. Logo depois, a Meta lançou seu próprio modelo, o LLaMa, e o Google lançou o Gemini. Todas as três empresas tinham grandes quantidades de texto para treinar seus modelos, mas um LLM precisa de outro ingrediente crucial: poder de computação para processar esse texto e, em seguida, gerar respostas às consultas do usuário. A empresa líder que fabrica as máquinas de computação é a Nvidia, cujas ações cresceram exponencialmente como resposta quando as guerras de LLM lideradas pela OpenAI/Microsoft, Google e Meta se seguiram.
As máquinas de computação são chamadas de GPUs — Unidades de Processamento Gráfico. Elas foram originalmente inventadas para processar gráficos de computador para jogos, como renderização 3D. Mais tarde, elas se tornaram populares porque suas capacidades de processamento paralelo as tornaram ideais para mineração de criptomoedas. Agora, ao que parece, elas também são ótimas em processamento de dados de IA por razões semelhantes. A Nvidia basicamente tem surfado ondas de booms à medida que diferentes mercados descobrem novos usos para seu produto.
Nos últimos anos, Meta, Google, Microsoft e OpenAI conseguiram acumularcentenas de milhares das GPUs mais avançadas e obter tratamento preferencial da Nvidia e de seu fornecedor, o principal fabricante mundial de semicondutores, a TSMC.
A indústria tecnológica americana tem tomado medidas significativas para se alinhar em torno da IA. As empresas têm adquirido startups, recrutado os melhores pesquisadores de IA e investido recursos no desenvolvimento de seus modelos primários de IA proprietários (chamados de modelos fundamentais), criando um fluxo de investimento em IA e tecnologias relacionadas, como computação em nuvem, fabricação avançada de chips e infraestrutura de dados. Tudo isso é uma tentativa de garantir o domínio no que eles afirmam ser a próxima fronteira da inovação tecnológica.
P: Como a China está envolvida?
R: Como parte de seu esforço maior para conter a China, o governo dos EUA tem a missão de impedir que empresas chinesas se tornem líderes em diferentes áreas de tecnologia. Ele fez isso exercendo controle sobre as cadeias de suprimentos globais e protegendo as empresas de tecnologia americanas da concorrência no processo. Os EUA bloquearam a entrada da Huawei no seu território no momento em que ela estava ultrapassando a Apple para se tornar a segunda maior fabricante de smartphonesdo mundoeimpediram que países europeus instalassem infraestrutura 5G fabricada pela Huawei quando era claramente mais econômica; e, mais recentemente, aprovaram uma legislação proibindoo TikTok, um aplicativo de mídia social chinês que se tornou extremamente popular nos Estados Unidos e cujo algoritmo de recomendação nenhum aplicativo de mídia social americano conseguiu superar.
A alegação dos EUA de que a Huawei e outras empresas de tecnologia chinesas estão inextricavelmente ligadas à estratégia geopolítica da China e colocam empresas e pessoas ocidentais em risco elevado de vigilância e espionagem corporativa é, claro, baseada na realidade.A DeepSeek não tem vergonhade quantos dados coleta em sua plataforma, incluindo até mesmo suas teclas digitadas:
Coletamos certas informações de conexão de dispositivo e rede quando você acessa o Serviço. Essas informações incluem o modelo do seu dispositivo, sistema operacional, padrões ou ritmos de pressionamento de tecla, endereço IP e idioma do sistema. Também coletamos informações relacionadas ao serviço, diagnóstico e desempenho, incluindo relatórios de falhas e logs de desempenho. Atribuímos automaticamente a você um ID de dispositivo e um ID de usuário. Quando você faz login em vários dispositivos, usamos informações como o ID do seu dispositivo e o ID do usuário para identificar sua atividade em todos os dispositivos para fornecer a você uma experiência de login perfeita e para fins de segurança.
No entanto, como o DeepSeek é de código aberto e pode ser executado localmente em um dispositivo separado, os olhos curiosos do presidente Xi Jinping podem ser protegidos.
Manter o domínio tecnológico global é uma das principais preocupações que os formuladores de políticas dos EUA têm repetidamentecitadoe identificado a IA como uma tecnologia crucial para manter esse domínio. Em 2018, quando o governo dos EUA estava no processo de banir a Huawei, percebeu que precisaria fazer o mesmo com tecnologias downstream, como chips semicondutores, o principal componente usado em CPUs e GPUs. A grave escassez de chips devido a interrupções na cadeia de suprimentos global durante a Covid-19 mostrou que chips avançados são um gargalo na cadeia de suprimentos global e um recurso escasso. Em 2022, o governo Biden impôssanções abrangentes à China, interrompendo a exportação desses chips para o país e impedindo que as empresas chinesas de IA acessassem as GPUs mais recentes e eficientes. Ao mesmo tempo, aprovou a lei CHIPS,subsidiando a fabricação nacional de semicondutores com mais de US$ 50 bilhões.
P: Por que todo mundo de repente está tão interessado em IA?
R: O nível exagerado de marketing e vendedor de óleo de cobra da indústria de IA dos EUA causou um certo pânico entre os formuladores de políticas governamentais menos alfabetizados tecnicamente. Muitos especialistas da indústria alegaram que os avanços em LLMs poderiam em breve levar à criação da Inteligência Artificial Geral (AGI), basicamente um computador que pensa como um ser humano e é bom em muitas tarefas diferentes. Algunsjásoaram o alarme de que ele pode se tornar maligno e autoconsciente. Mas até mesmo seus detratores concordaram que os LLMs são uma tecnologia revolucionária que mudará fundamentalmente a forma como interagimos com os computadores.
P: Por que os caras da tecnologia estão tão bravos?
Grandes empresas de tecnologia também têm dito ao governo e investidores que construir IA é muito, muito caro. Em sua primeira semana no cargo, o presidente dos EUA, Donald Trump, anunciou US$ 500 bilhões em investimentos do setor privado em IA sob um projeto chamado Stargate— uma colaboração entre OpenAI, Softbank e Oracle.
No passado, o fundador da OpenAI, Sam Altman, afirmou que precisaria de até US$ 7 trilhões para criar sua IA dos sonhos e estava levantando investimentos usando essa meta. Para contextualizar, nenhum homem em toda a história do mundo já gastou essa quantia de dinheiro em uma única coisa. Mas a mensagem subjacente parece ser: esta é uma tecnologia mágica e uma força mais poderosa do que qualquer outra que o mundo já viu, precisamos de quantias astronômicas de dinheiro para construí-la e precisamos da proteção do governo dos EUA enquanto fazemos isso.
Então veio uma pequena empresa chinesa que estourou essa bolha com seu projeto paralelo. Ela usouUS$ 5,5 milhões em poder computacional para fazer isso, usando apenas 2.048 GPUs Nvidia H800que a empresa chinesa tinha porquenão podia comprar as GPUs superiores H100 ou A100 que as empresas americanas estão reunindo em centenas de milhares.
Para contextualizar, a Meta AI estabeleceu a meta de possuir um cluster de 600.000 GPUs H100 até o final de 2024. Elon Musk tem 100.000 GPUs, enquanto a OpenAItreinou seu modelo GPT-4em aproximadamente 25.000 GPUs A100. Enquanto isso, a DeepSeek foi fundada pelagestora de fundos de hedge chinesa High Flyerque queria colocar seu cluster de, de acordo com amídia chinesa , 10.000 GPUs H800 em bom uso.
A DeepSeek, de acordo coma tradição , contratou uma equipe muito jovem e os impulsionou a inovar e aproveitar ao máximo seu hardware limitado. Eles lançaram o modelo DeepSeek-V3 no mês passado, um modelo que supera o OpenAI GPT-4 e todos os outros modelos do setor na maioria dos benchmarks. Não há nenhum desenvolvimento significativo na tecnologia básica, eles apenas usam o hardware de forma eficiente e treinam melhor seu modelo.
Os manos da tecnologia são salgados porque isso os faz parecer ruins. O que complica ainda mais as coisas é que o DeepSeek lançou seu modelo e métodos de treinamento como software de código aberto, o que significa que qualquer um pode ver como eles fizeram seu modelo ereplicar o processo. Isso também significa que os usuários podem instalar modelos do DeepSeek em suas próprias máquinas e executá-los em suas próprias GPUs , onde eles parecem estar tendo um desempenho muito bom.
“Deepseek é uma operação psicológica do estado do Partido Comunista da China+ guerra econômica para tornar a IA americana não lucrativa. Eles estão fingindo que o custo era baixo para justificar a fixação de um preço baixo e esperando que todos mudem para ele, prejudicando a competitividade da IA nos EUA, não morda a isca”,tuitouNeal Khosla, filho do investidor Vinod Khosla. A Khosla Ventures levantou mais de US$ 400 milhõespara a OpenAI e é um dos maiores investidores da empresa.
“O DeepSeek é um alerta para a América”,disse Alexandr Wang, fundador da empresa de IA Scale AI, e alguém que acusou mais notavelmente o DeepSeek de esconder um estoque secreto de 50.000 GPUs H100.
“As acusações/obsessões sobre o DeepSeek usar o H100 parecem como se um time de crianças ricas tivesse sido derrotado por um time de crianças pobres, que nem sequer tinham permissão para usar sapatos”, tuitou Jen Zhu, um investidor em IA, “e agora as crianças ricas estão exigindo uma investigação para saber se sapatos foram usados em vez de treinar mais para se aprimorarem”.
P: Por que o mercado de ações está despencando?
R: Embora o DeepSeek v3 já esteja disponível há quase um mês, as notícias estão começando a chegar ao mercado somente agora. As ações da Nvidia caíram quase 15% antes do mercado na segunda-feira, perdendo aproximadamente US$ 420 bilhões de sua capitalização de mercado edesencadeando um banho de sanguenas ações de semicondutores que poderia varrer US$ 1 trilhão do mercado de ações em um único dia. Quando foi lançado no final de dezembro, Andrej Karpathy, um importante cientista na área, comentousobre sua eficiência surpreendente, mas as repercussões de uma empresa chinesa desconhecida lançando um modelo fundamental de código aberto só decolaram quando o Vale do Silício começou a testar o DeepSeek em seus computadores pessoais e o DeepSeek subiu para o aplicativo número um .
Ironicamente, os caras da tecnologia surtando e gerando níveis de conflitonunca antes vistos estão contribuindo para a viralidade do DeepSeek.
DeepSeek lançou um concorrente ChatGPT e Llama usando chips de capacidade reduzida da Nvidia
Por Rocio Fabbro para o “Quartz”
As ações da Nvidia ( NVDA ) caíram até 14% no pré-mercado na segunda-feira, depois que o modelo mais recente da startup chinesa de inteligência artificial (IA) DeepSeek levantou questões sobre a competitividade americana no espaço da IA.
A DeepSeek lançou em dezembro um modelo de linguagem grande (LLM) de código aberto e gratuito, que ela alegou ter desenvolvido em apenas dois meses por menos de US$ 6 milhões. E na semana passada, a empresa disse que lançou um modelo que rivaliza com o ChatGPT da OpenAI e o Llama 3.1 da Meta ( META ) — e que chegou ao topo da App Store da Apple ( AAPL ) no fim de semana.
Mais notavelmente, a DeepSeek construiu o modelo usando chips de menor capacidade da Nvidia, o que pode pressionar a queridinha dos semicondutores se outras empresas se afastarem de suas ofertas premium.
Analistas da Wedbush disseram em uma nota de pesquisa na segunda-feira que “as ações de tecnologia estão sob enorme pressão liderada pela Nvidia, já que a Wall Street verá o DeepSeek como uma grande ameaça percebida ao domínio da tecnologia dos EUA e à posse desta Revolução da IA”.
As ações da Nvidia caíram quase 12% na manhã de segunda-feira. A notícia fez outras grandes ações de chips caírem, incluindo a ASML ( ASML ), que caiu 7%, e a Broadcom ( AVGO ), que teve uma queda de 12%.A liquidação fez o índice Nasdaq, pesado em tecnologia, cair no pré-mercado , com os futuros quase 4% mais baixos.
“As empresas de tecnologia dos EUA estão sendo negociadas com avaliações premium, com grandes players de IA como Nvidia, Microsoft ( MSFT ) e Alphabet ( GOOGL ) comandando múltiplos [preço-lucro] futuros muito acima das médias históricas”, disse Charu Chanana, estrategista-chefe de investimentos na plataforma de investimentos Saxo, em uma declaração. “Com essas ações precificadas para a perfeição, até mesmo pequenas interrupções, como a DeepSeek provando que a IA avançada pode ser construída sem chips de primeira linha, podem pesar muito nos preços das ações.”
Com o objetivo final da IA sendo a inteligência artificial geral (AGI) — e com as empresas dos EUA bem encaminhadas para alcançá-la nos próximos anos — os analistas da Wedbush acreditam que o nervosismo dos investidores de segunda-feira pode ser exagerado.
“Embora o modelo seja impressionante e tenha um impacto cascata”, eles disseram, “a realidade é que a Mag 7 e a tecnologia dos EUA estão focadas no jogo final da AGI com toda a infraestrutura e ecossistema que a China e especialmente a DeepSeek não conseguem chegar perto, em nossa opinião”.