A discussão sobre a Taxonomia de Bloom revela um dilema muito mais profundo: a Uenf permanecerá fiel ao projeto universitário concebido por Darcy Ribeiro ou adotará, de forma crescente, a lógica gerencial que transforma professores em executores de protocolos e indicadores?

Recentemente, li com atenção o tutorial “Elaboração e Cadastro de Disciplinas no Sistema Acadêmico“, elaborado pela Pró-Reitoria de Graduação (ProGrad) da Universidade Estaudla do Norte Fluminense Darcy Ribeiro (Uenf). O documento busca orientar os docentes na elaboração dos programas analíticos das disciplinas e oferece contribuições importantes para organizar ementas, conteúdos programáticos, bibliografias e procedimentos administrativos. À primeira vista se trata de um esforço legítimo de qualificação da gestão acadêmica. Mas foi justamente essa leitura que despertou uma reflexão que extrapola o próprio documento. Ao estabelecer que os objetivos das disciplinas devem ser formulados utilizando verbos da Taxonomia de Bloom, o tutorial transforma uma ferramenta pedagógica em referência normativa para a elaboração dos programas das disciplinas.
Faço questão de deixar claro que esta reflexão não constitui uma crítica à Taxonomia de Bloom. Ao contrário, ela permanece uma das contribuições mais importantes para o planejamento pedagógico produzidas no século XX e continua sendo extremamente útil para milhares de professores em todo o mundo. O problema começa quando uma ferramenta de apoio deixa de ser uma possibilidade metodológica entre várias existentes e passa a funcionar como linguagem institucional obrigatória. Nesse momento, a discussão deixa de ser exclusivamente pedagógica e passa a envolver a própria concepção de universidade que estamos construindo.
A universidade pública sempre se caracterizou pelo pluralismo de ideias e de concepções pedagógicas. Professores organizam suas disciplinas a partir de referenciais distintos, formulam objetivos educacionais de maneiras diferentes e constroem estratégias de ensino compatíveis com suas áreas de conhecimento. Essa diversidade não representa uma deficiência administrativa; ela constitui uma das expressões concretas da liberdade de cátedra assegurada pela Constituição Federal e uma condição indispensável para a produção de conhecimento crítico.
Entretanto, essa autonomia passou a conviver, nas últimas décadas, com uma lógica institucional bastante diferente. Desde os anos 1990, universidades em praticamente todo o mundo passaram por reformas inspiradas na chamada Nova Gestão Pública (New Public Management). Inicialmente apresentadas como mecanismos para aumentar a eficiência do setor público, essas reformas introduziram nas universidades princípios oriundos da administração empresarial, como indicadores de desempenho, metas, competências, auditorias, plataformas digitais e procedimentos padronizados.
Nenhum desses instrumentos parece problemático quando considerado isoladamente. O problema surge quando eles passam a reorganizar o cotidiano universitário. A atividade docente começa a ser mediada por novos formulários, novos indicadores, novos protocolos, novos sistemas digitais e novos critérios de avaliação. Cada uma dessas mudanças pode parecer tecnicamente justificável. Em conjunto, porém, elas alteram profundamente a cultura institucional. O tempo dedicado ao planejamento pedagógico, à reflexão científica e ao acompanhamento dos estudantes passa a disputar espaço com o preenchimento de plataformas digitais, a produção permanente de registros administrativos e a necessidade de demonstrar conformidade com protocolos institucionais. A atividade intelectual vai sendo reorganizada segundo critérios administrativos.
Foi exatamente esse processo que Marilena Chauí descreveu ao formular a ideia da universidade operacional. Segundo a filósofa, a universidade deixa gradualmente de se orientar pela produção crítica do conhecimento e passa a organizar suas atividades segundo critérios de eficiência, produtividade e desempenho. Já Stephen Ball identifica movimento semelhante ao analisar aquilo que denomina cultura da performatividade, na qual a confiança na autonomia profissional dos docentes cede lugar a indicadores destinados a medir, comparar e auditar continuamente seu desempenho. O centro da atividade universitária desloca-se do conteúdo do trabalho acadêmico para a produção de evidências documentais de que esse trabalho atende aos padrões previamente estabelecidos.
É justamente nesse contexto que a Taxonomia de Bloom muda de função. Benjamin Bloom jamais concebeu sua taxonomia como mecanismo de controle institucional. A intenção de Bloom era oferecer aos professores um instrumento para refletir sobre diferentes níveis de aprendizagem. No ambiente da universidade gerencializada, porém, essa ferramenta passa a facilitar a padronização dos programas das disciplinas, a produção de documentos comparáveis e a redução da diversidade de linguagens pedagógicas. Com isso, Bloom deixa de ser apenas uma ferramenta didática para integrar uma tecnologia de gestão.
Não creio que esse tenha sido o objetivo da ProGrad ao elaborar seu tutorial. Ao contrário, o documento demonstra uma preocupação legítima com a qualidade dos programas das disciplinas e com a organização institucional. O problema reside no fato de que essa racionalidade gerencial tornou-se tão naturalizada nas universidades que frequentemente deixa de ser percebida como uma escolha política. Como argumentam Pierre Dardot e Christian Laval em A Nova Razão do Mundo, o neoliberalismo não constitui apenas um conjunto de políticas econômicas. Ele representa uma racionalidade que reorganiza instituições inteiras segundo princípios de competição, mensuração, desempenho e controle, apresentando essas transformações como se fossem meramente técnicas e inevitáveis.
Uma universidade pública precisa, evidentemente, de organização institucional. Precisa de programas consistentes, ementas claras, bibliografias atualizadas e critérios transparentes de avaliação. Mas organização não deve significar uniformização pedagógica. Talvez bastasse uma pequena alteração na redação do tutorial para preservar esse equilíbrio. Em vez de afirmar que os objetivos das disciplinas devem utilizar a Taxonomia de Bloom, seria suficiente reconhecê-la como uma referência pedagógica recomendada, entre outras igualmente legítimas.

Ao final dessa reflexão, contudo, permanece uma questão que ultrapassa em muito a redação dos objetivos de uma disciplina. Ela nos remete ao próprio projeto de universidade que desejamos construir. Darcy Ribeiro imaginou a Uenf como a Universidade do Terceiro Milênio: uma instituição inovadora, interdisciplinar, voltada para a produção de conhecimento de fronteira e comprometida com a transformação da realidade brasileira. Nada indica que Darcy rejeitasse planejamento, organização administrativa ou mecanismos de avaliação. A trajetória de Darcy demonstra exatamente o contrário. O que parece muito menos compatível com seu pensamento é a substituição gradual da confiança na autonomia intelectual de seus professores por uma cultura baseada em protocolos, indicadores, plataformas digitais, métricas de desempenho e padronizações administrativas. Essa talvez seja uma das manifestações mais discretas — e justamente por isso mais eficazes — da racionalidade neoliberal nas universidades públicas. Ela não elimina formalmente a liberdade de cátedra, mas tende a restringi-la por meio da normalização das práticas acadêmicas.
Desta forma, se a Uenf pretende permanecer fiel ao projeto concebido por Darcy Ribeiro, precisará perguntar continuamente se cada nova norma, cada novo protocolo e cada novo sistema fortalecem a criatividade científica e a liberdade intelectual ou se aproximam a instituição dos cânones da universidade neoliberal. Essa talvez seja a pergunta mais importante que a comunidade universitária precisa enfrentar, porque dela depende não apenas a preservação da liberdade de cátedra, mas também a capacidade da Uenf de continuar sendo, no sentido mais profundo imaginado por Darcy Ribeiro, uma verdadeira Universidade do Terceiro Milênio.











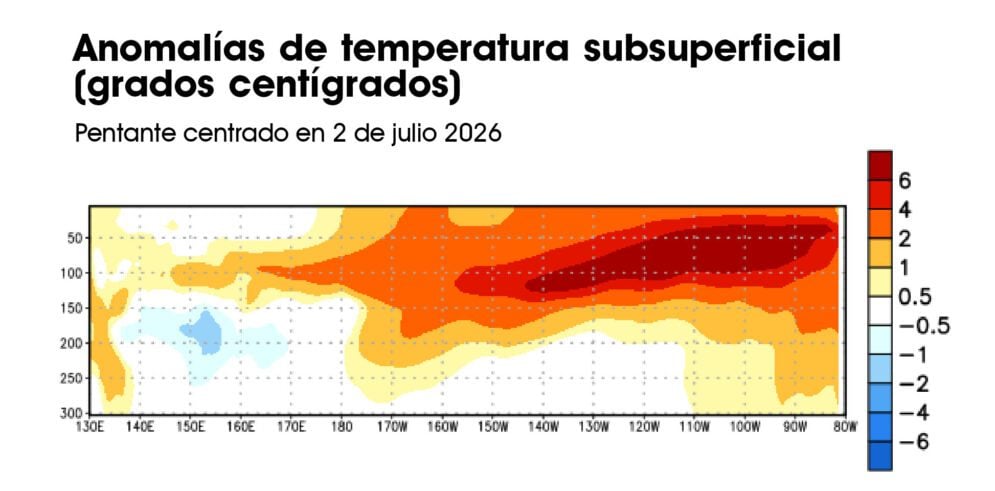
 As famílias mais vulneráveis são prejudicadas por fenômenos como o Super Niño, pois já sofrem com diversas privações que são agravadas pela emergência climática. Crédito da imagem: John Reyes/Diario La República.
As famílias mais vulneráveis são prejudicadas por fenômenos como o Super Niño, pois já sofrem com diversas privações que são agravadas pela emergência climática. Crédito da imagem: John Reyes/Diario La República. A anchova é o principal insumo da indústria pesqueira peruana, mas sua captura está agora em risco devido ao aquecimento das águas do Pacífico causado pelo El Niño. Crédito da imagem: Ministério da Produção (Produce-Peru). Imagem em domínio público.
A anchova é o principal insumo da indústria pesqueira peruana, mas sua captura está agora em risco devido ao aquecimento das águas do Pacífico causado pelo El Niño. Crédito da imagem: Ministério da Produção (Produce-Peru). Imagem em domínio público.
 Os incêndios florestais podem se tornar mais frequentes na Amazônia devido à falta de chuvas causada pelo fenômeno. Crédito: Serfor/Peru, imagem em domínio público.
Os incêndios florestais podem se tornar mais frequentes na Amazônia devido à falta de chuvas causada pelo fenômeno. Crédito: Serfor/Peru, imagem em domínio público. A tempestade que vem atingindo diversas regiões tradicionalmente secas do Chile desde 1º de julho causou mortes, feridos e deixou milhares de pessoas desabrigadas. Crédito da imagem: Marinha do Chile/Directemar.
A tempestade que vem atingindo diversas regiões tradicionalmente secas do Chile desde 1º de julho causou mortes, feridos e deixou milhares de pessoas desabrigadas. Crédito da imagem: Marinha do Chile/Directemar. Muitos países africanos são altamente vulneráveis a eventos climáticos extremos, como o Super Niño. Crédito da imagem: Cortesia da OMM (Organização Meteorológica Mundial).
Muitos países africanos são altamente vulneráveis a eventos climáticos extremos, como o Super Niño. Crédito da imagem: Cortesia da OMM (Organização Meteorológica Mundial).




{kind=link}
{kind=link}