O logotipo da empresa chinesa de inteligência artificial DeepSeek é visto em Hangzhou, província de Zhejiang, China, em 26 de janeiro de 2025. CFOTO/Future Publishing via Getty Images
Por Ryan Grim e Waqas Ahmed para o DropSite
As ações de tecnologia dos EUA estão despencando enquanto a China parece estar expondo as empresas americanas envolvidas em Inteligência Artificial (IA) como extremamente supervalorizadas. É uma consequência previsível de como o governo americano abordou o Vale do Silício e vice-versa. Este não é o tipo de coisa que normalmente cobrimos, mas não confiamos muito na mídia dos EUA para contar essa história com precisão.
Qualquer um que acompanha casualmente viu como foi. Empresas de tecnologia dos EUA, com o apoio do governo federal (e do Pentágono), construíram uma posição global dominante por meio de inovação genuína. Microsoft, Facebook, Apple, Google e Amazon remodelaram o mundo. A Microsoft, uma das primeiras grandes empresas a crescer, tentou interromper essa inovação comprando e/ou esmagando seus concorrentes, mas os EUA a processaram em 1998 por violar as leis antitruste. O governo Bush resolveu o caso, recuando no esforço de separá-los. O que se seguiu foi um abraço bipartidário da Big Tech; as eras Bush e Obama viram crescimento desenfreado e fusões. À medida que as empresas de tecnologia viam empresas menores inovando, elas compravam a empresa, a matavam e absorviam parte de sua equipe.
Um movimento antimonopólio começou a borbulhar, levando a processos judiciais contra Facebook, Amazon, Google e Apple na última década. Lina Khan, como presidente da Comissão Federal de Comércio sob o ex-presidente Joe Biden, tornou-se uma heroína popular ao alertar que a ganância e a consolidação não estavam prejudicando apenas consumidores e trabalhadores, mas que as próprias empresas escleróticas acabariam sofrendo com a falta de concorrência. “Nossa história mostra que manter mercados abertos, justos e competitivos, especialmente em pontos de inflexão tecnológica, é uma maneira fundamental de garantir que a América se beneficie da inovação que essas ferramentas podem catalisar”, disse Khan em 2023.
Agora ficou claro que o fosso que os EUA construíram para proteger suas empresas da concorrência doméstica na verdade criou as condições que permitiram que elas atrofiassem. Elas ficaram gordas e felizes dentro de seus castelos. Seus negócios mudaram da inovação tecnológica para a realização de alquimia com planilhas, transformando métricas inventadas em avaliações em dólares desvinculadas da realidade. Agora, a DeepSeek expôs o golpe. Com uma pequena fração dos recursos e sem acesso a toda a panóplia de tecnologia de chips dos EUA, a empresa chinesa DeepSeek enganou o Vale do Silício. A empresa americana OpenAI começou como uma organização sem fins lucrativos dedicada a tornar a IA amplamente disponível, como seu nome sugere. Seu chefe, Sam Altman, conseguiu transformá-la em uma empresa com fins lucrativos e fechá-la.
Agora, o DeepSeek está ironicamente cumprindo a missão original do OpenAI ao fornecer um modelo de código aberto que simplesmente tem melhor desempenho do que qualquer outro no mercado.
Enquanto isso, aqui nos Estados Unidos, Trump está comemorando um investimento (possivelmente exagerado) de US$ 500 bilhões no Texas para abastecer o poder computacional de IA que parece estar obsoleto — ou muito menos relevante — graças à inovação da DeepSeek. E Trump está enchendo sua administração com manos da criptografia, magnatas da tecnologia se recusando a desinvestir e até lançou sua própria moeda meme de golpe. Os principais conselheiros de tecnologia de Trump, como Elon Musk, enquanto isso, têm extensos laços comerciais diretamente com a China. Você não precisa apertar os olhos muito para ver qual desses países vai ganhar essa competição.
O contrato social firmado entre o governo dos EUA e o Vale do Silício — do qual o povo americano se tornou parte involuntária — era direto: deixaremos um punhado de caras da tecnologia se tornarem incomensuravelmente ricos e, em troca, eles construirão uma indústria de tecnologia que manterá a América globalmente dominante. Em vez disso, os caras da tecnologia quebraram o acordo. Eles pegaram o dinheiro, mas em vez de continuar a inovar e competir, construíram monopólios para manter a concorrência fora — até mesmo recebendo a ajuda do estado de segurança nacional dos EUA para bloquear o acesso chinês à nossa tecnologia. Mas eles não conseguiram ficar fora da competição para sempre. Lina Khan estava certa. E agora aqui estamos.
Os efeitos posteriores serão profundos se a trajetória de uma transferência de riqueza dos EUA para a China continuar acelerada. É comum dizer que a maioria das pessoas não possui ações individuais, mas isso subestima a exposição que todos nós temos a esse golpe. Está em nossos IRAs ou 401ks e a ascensão dessas ações constituiu quase todo o crescimento do mercado de ações nos últimos anos. E se a China se tornar cada vez mais o lugar para trabalhar se você for um pesquisador ou desenvolvedor ambicioso, não é difícil ver aonde isso leva.
Abaixo está uma explicação sobre o DeepSeek que pedimos ao nosso correspondente Waqas Ahmed para elaborar.
CEO da OpenAI, Sam Altman. Foto de Justin Sullivan/Getty Images.
P: O que é DeepSeek e por que ele está causando um colapso nas ações?
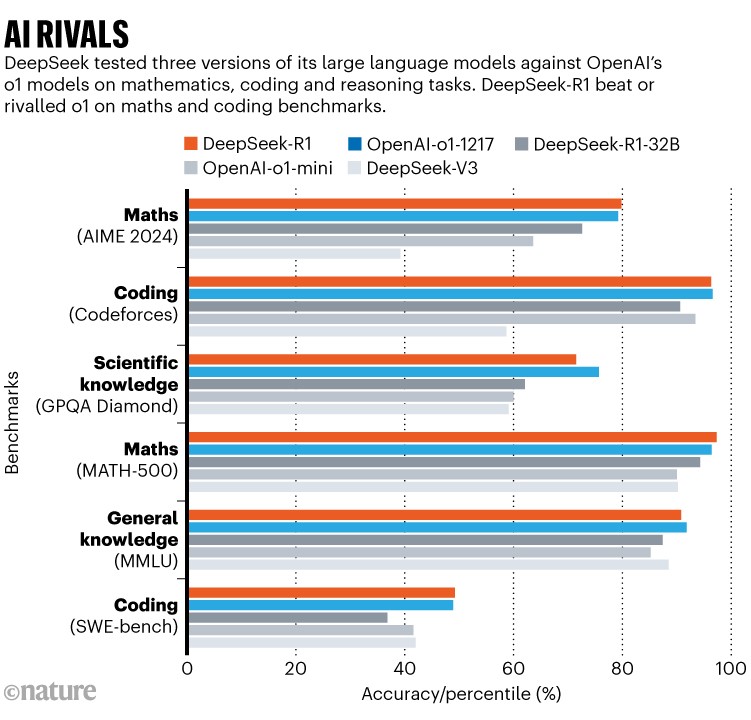
R: A empresa chinesa DeepSeek lançou um modelo de IA que é tão bom quanto qualquer um de seus equivalentes americanos e o tornou de código aberto. Isso mudou fundamentalmente a economia e a política da indústria de IA em rápido crescimento, que até agora tem sido liderada por um oligopólio de empresas de tecnologia americanas tentando posicionar os Large Language Models (LLMs) como o avanço tecnológico definidor deste século, e eles próprios como os guardiões de seu molho secreto.
Há muita conversa sobre o DeepSeek custar apenas cerca de US$ 6 milhões para ser construído, embora esse valor não inclua pesquisa e desenvolvimento. E, apesar dos controles de exportação, o DeepSeek conseguiu explorar um número não trivial de chips de alta tecnologia que estávamos tentando manter deles. No entanto, ainda é um choque enorme para a indústria dos EUA.
P: O que são LLMs e como eles surgiram ?
R: Um artigo de 2017 intitulado “Atenção é tudo o que você precisa ” foi um ponto de virada na indústria de IA. O artigo descreveu um método de criação de um modelo de aprendizado de máquina que poderia produzir texto semelhante ao humano com precisão e escala sem precedentes usando uma arquitetura chamada “transformadores”. Esses “transformadores” melhoraram consideravelmente uma classe de modelos chamados Large Language Models (LLMs). Os LLMs usam grandes quantidades de texto — livros, artigos, e-mails, receitas, perguntas frequentes, tudo — para criar representações matemáticas internas de relacionamentos entre bilhões de palavras e frases — ou, mais precisamente, entre combinações de tokens encontrados em uma linguagem humana natural.
Antes de 2017, os LLMs não eram muito úteis, mas os “transformadores” mudaram isso. Ao processar grandes quantidades de texto usando a arquitetura do transformador, esses modelos agora podiam “aprender” o que as palavras significam em diferentes contextos e detectar nuances que os computadores nunca tinham conseguido antes, permitindo que esses modelos produzissem texto extremamente relevante em resposta a um prompt ou pergunta do usuário.
P: Como começou o entusiasmo pela IA?
R: A OpenAI se tornou a primeira empresa americana a demonstrar que se você tirar um instantâneo de toda a internet conhecida e de todos os livros digitalizados existentes sem se preocupar muito com a lei de direitos autorais , você pode criar um modelo tão bom que sua saída seria quase indistinguível daquela de um burocrata de DC com inteligência medíocre. No entanto, a OpenAI mostrou que seu modelo poderia ser treinado para ter experiência em diferentes domínios e poderia dar respostas aprofundadas a perguntas muito específicas. Seu modelo passou em exames de codificação, no exame da ordem e se formou na escola de negócios. Os resultados foram tão chocantes que a OpenAI saiu e afirmou que valia um zilhão de dólares e que o futuro da humanidade dependia disso.
P: Qual é o estado atual do setor de IA?
R: A OpenAI, parcialmente de propriedade da Microsoft, foi a primeira a lançar um grande produto LLM, o ChatGPT, em novembro de 2022. Logo depois, a Meta lançou seu próprio modelo, o LLaMa, e o Google lançou o Gemini. Todas as três empresas tinham grandes quantidades de texto para treinar seus modelos, mas um LLM precisa de outro ingrediente crucial: poder de computação para processar esse texto e, em seguida, gerar respostas às consultas do usuário. A empresa líder que fabrica as máquinas de computação é a Nvidia, cujas ações cresceram exponencialmente como resposta quando as guerras de LLM lideradas pela OpenAI/Microsoft, Google e Meta se seguiram.
As máquinas de computação são chamadas de GPUs — Unidades de Processamento Gráfico. Elas foram originalmente inventadas para processar gráficos de computador para jogos, como renderização 3D. Mais tarde, elas se tornaram populares porque suas capacidades de processamento paralelo as tornaram ideais para mineração de criptomoedas. Agora, ao que parece, elas também são ótimas em processamento de dados de IA por razões semelhantes. A Nvidia basicamente tem surfado ondas de booms à medida que diferentes mercados descobrem novos usos para seu produto.
Nos últimos anos, Meta, Google, Microsoft e OpenAI conseguiram acumular centenas de milhares das GPUs mais avançadas e obter tratamento preferencial da Nvidia e de seu fornecedor, o principal fabricante mundial de semicondutores, a TSMC.
A indústria tecnológica americana tem tomado medidas significativas para se alinhar em torno da IA. As empresas têm adquirido startups, recrutado os melhores pesquisadores de IA e investido recursos no desenvolvimento de seus modelos primários de IA proprietários (chamados de modelos fundamentais), criando um fluxo de investimento em IA e tecnologias relacionadas, como computação em nuvem, fabricação avançada de chips e infraestrutura de dados. Tudo isso é uma tentativa de garantir o domínio no que eles afirmam ser a próxima fronteira da inovação tecnológica.
P: Como a China está envolvida?
R: Como parte de seu esforço maior para conter a China, o governo dos EUA tem a missão de impedir que empresas chinesas se tornem líderes em diferentes áreas de tecnologia. Ele fez isso exercendo controle sobre as cadeias de suprimentos globais e protegendo as empresas de tecnologia americanas da concorrência no processo. Os EUA bloquearam a entrada da Huawei no seu território no momento em que ela estava ultrapassando a Apple para se tornar a segunda maior fabricante de smartphones do mundo e impediram que países europeus instalassem infraestrutura 5G fabricada pela Huawei quando era claramente mais econômica; e, mais recentemente, aprovaram uma legislação proibindo o TikTok, um aplicativo de mídia social chinês que se tornou extremamente popular nos Estados Unidos e cujo algoritmo de recomendação nenhum aplicativo de mídia social americano conseguiu superar.
A alegação dos EUA de que a Huawei e outras empresas de tecnologia chinesas estão inextricavelmente ligadas à estratégia geopolítica da China e colocam empresas e pessoas ocidentais em risco elevado de vigilância e espionagem corporativa é, claro, baseada na realidade. A DeepSeek não tem vergonha de quantos dados coleta em sua plataforma, incluindo até mesmo suas teclas digitadas:
Coletamos certas informações de conexão de dispositivo e rede quando você acessa o Serviço. Essas informações incluem o modelo do seu dispositivo, sistema operacional, padrões ou ritmos de pressionamento de tecla, endereço IP e idioma do sistema. Também coletamos informações relacionadas ao serviço, diagnóstico e desempenho, incluindo relatórios de falhas e logs de desempenho. Atribuímos automaticamente a você um ID de dispositivo e um ID de usuário. Quando você faz login em vários dispositivos, usamos informações como o ID do seu dispositivo e o ID do usuário para identificar sua atividade em todos os dispositivos para fornecer a você uma experiência de login perfeita e para fins de segurança.
No entanto, como o DeepSeek é de código aberto e pode ser executado localmente em um dispositivo separado, os olhos curiosos do presidente Xi Jinping podem ser protegidos.
Manter o domínio tecnológico global é uma das principais preocupações que os formuladores de políticas dos EUA têm repetidamente citado e identificado a IA como uma tecnologia crucial para manter esse domínio . Em 2018, quando o governo dos EUA estava no processo de banir a Huawei, percebeu que precisaria fazer o mesmo com tecnologias downstream, como chips semicondutores, o principal componente usado em CPUs e GPUs. A grave escassez de chips devido a interrupções na cadeia de suprimentos global durante a Covid-19 mostrou que chips avançados são um gargalo na cadeia de suprimentos global e um recurso escasso. Em 2022, o governo Biden impôs sanções abrangentes à China, interrompendo a exportação desses chips para o país e impedindo que as empresas chinesas de IA acessassem as GPUs mais recentes e eficientes. Ao mesmo tempo, aprovou a lei CHIPS, subsidiando a fabricação nacional de semicondutores com mais de US$ 50 bilhões.
P: Por que todo mundo de repente está tão interessado em IA?
R: O nível exagerado de marketing e vendedor de óleo de cobra da indústria de IA dos EUA causou um certo pânico entre os formuladores de políticas governamentais menos alfabetizados tecnicamente. Muitos especialistas da indústria alegaram que os avanços em LLMs poderiam em breve levar à criação da Inteligência Artificial Geral (AGI), basicamente um computador que pensa como um ser humano e é bom em muitas tarefas diferentes. Alguns já soaram o alarme de que ele pode se tornar maligno e autoconsciente. Mas até mesmo seus detratores concordaram que os LLMs são uma tecnologia revolucionária que mudará fundamentalmente a forma como interagimos com os computadores.
P: Por que os caras da tecnologia estão tão bravos?
Grandes empresas de tecnologia também têm dito ao governo e investidores que construir IA é muito, muito caro. Em sua primeira semana no cargo, o presidente dos EUA, Donald Trump, anunciou US$ 500 bilhões em investimentos do setor privado em IA sob um projeto chamado Stargate — uma colaboração entre OpenAI, Softbank e Oracle.
No passado, o fundador da OpenAI, Sam Altman, afirmou que precisaria de até US$ 7 trilhões para criar sua IA dos sonhos e estava levantando investimentos usando essa meta. Para contextualizar, nenhum homem em toda a história do mundo já gastou essa quantia de dinheiro em uma única coisa. Mas a mensagem subjacente parece ser: esta é uma tecnologia mágica e uma força mais poderosa do que qualquer outra que o mundo já viu, precisamos de quantias astronômicas de dinheiro para construí-la e precisamos da proteção do governo dos EUA enquanto fazemos isso.
Então veio uma pequena empresa chinesa que estourou essa bolha com seu projeto paralelo. Ela usou US$ 5,5 milhões em poder computacional para fazer isso, usando apenas 2.048 GPUs Nvidia H800 que a empresa chinesa tinha porque não podia comprar as GPUs superiores H100 ou A100 que as empresas americanas estão reunindo em centenas de milhares.
Para contextualizar, a Meta AI estabeleceu a meta de possuir um cluster de 600.000 GPUs H100 até o final de 2024. Elon Musk tem 100.000 GPUs, enquanto a OpenAI treinou seu modelo GPT-4 em aproximadamente 25.000 GPUs A100. Enquanto isso, a DeepSeek foi fundada pela gestora de fundos de hedge chinesa High Flyer que queria colocar seu cluster de, de acordo com a mídia chinesa , 10.000 GPUs H800 em bom uso.
A DeepSeek, de acordo com a tradição , contratou uma equipe muito jovem e os impulsionou a inovar e aproveitar ao máximo seu hardware limitado. Eles lançaram o modelo DeepSeek-V3 no mês passado, um modelo que supera o OpenAI GPT-4 e todos os outros modelos do setor na maioria dos benchmarks. Não há nenhum desenvolvimento significativo na tecnologia básica, eles apenas usam o hardware de forma eficiente e treinam melhor seu modelo.
Os manos da tecnologia são salgados porque isso os faz parecer ruins. O que complica ainda mais as coisas é que o DeepSeek lançou seu modelo e métodos de treinamento como software de código aberto, o que significa que qualquer um pode ver como eles fizeram seu modelo e replicar o processo. Isso também significa que os usuários podem instalar modelos do DeepSeek em suas próprias máquinas e executá-los em suas próprias GPUs , onde eles parecem estar tendo um desempenho muito bom.
P: Como os caras da tecnologia estão reagindo?
R: Embora tenha havido uma mudança significativa na vibração em direção a “acabou “, alguns ainda afirmam que “estamos de volta ” e este é o “momento Sputnik da IA “. Outros não foram tão magnânimos.
“Deepseek é uma operação psicológica do estado do Partido Comunista da China+ guerra econômica para tornar a IA americana não lucrativa. Eles estão fingindo que o custo era baixo para justificar a fixação de um preço baixo e esperando que todos mudem para ele, prejudicando a competitividade da IA nos EUA, não morda a isca”, tuitou Neal Khosla, filho do investidor Vinod Khosla. A Khosla Ventures levantou mais de US$ 400 milhões para a OpenAI e é um dos maiores investidores da empresa.
“O DeepSeek é um alerta para a América”, disse Alexandr Wang, fundador da empresa de IA Scale AI, e alguém que acusou mais notavelmente o DeepSeek de esconder um estoque secreto de 50.000 GPUs H100.
“As acusações/obsessões sobre o DeepSeek usar o H100 parecem como se um time de crianças ricas tivesse sido derrotado por um time de crianças pobres, que nem sequer tinham permissão para usar sapatos”, tuitou Jen Zhu, um investidor em IA, “e agora as crianças ricas estão exigindo uma investigação para saber se sapatos foram usados em vez de treinar mais para se aprimorarem”.
P: Por que o mercado de ações está despencando?
R: Embora o DeepSeek v3 já esteja disponível há quase um mês, as notícias estão começando a chegar ao mercado somente agora. As ações da Nvidia caíram quase 15% antes do mercado na segunda-feira, perdendo aproximadamente US$ 420 bilhões de sua capitalização de mercado e desencadeando um banho de sangue nas ações de semicondutores que poderia varrer US$ 1 trilhão do mercado de ações em um único dia. Quando foi lançado no final de dezembro, Andrej Karpathy, um importante cientista na área, comentou sobre sua eficiência surpreendente, mas as repercussões de uma empresa chinesa desconhecida lançando um modelo fundamental de código aberto só decolaram quando o Vale do Silício começou a testar o DeepSeek em seus computadores pessoais e o DeepSeek subiu para o aplicativo número um .
Ironicamente, os caras da tecnologia surtando e gerando níveis de conflito nunca antes vistos estão contribuindo para a viralidade do DeepSeek.
Fonte: DropSite