O DeepSeek-R1 executa tarefas de raciocínio no mesmo nível que o o1 da OpenAI — e está aberto para análise por pesquisadores
 A empresa chinesa DeepSeek estreou uma versão de seu grande modelo de linguagem no ano passado. Crédito: Koshiro K/Alamy
A empresa chinesa DeepSeek estreou uma versão de seu grande modelo de linguagem no ano passado. Crédito: Koshiro K/Alamy
Por Elizabeth Gibney para a “Nature”
Um grande modelo de linguagem desenvolvido na China, chamado DeepSeek-R1, está entusiasmando os cientistas como um rival acessível e aberto aos modelos de “raciocínio” como o o1 da OpenAI.
Esses modelos geram respostas passo a passo, em um processo análogo ao raciocínio humano. Isso os torna mais aptos do que os modelos de linguagem anteriores para resolver problemas científicos, e significa que eles podem ser úteis em pesquisas . Os testes iniciais do R1, lançado em 20 de janeiro, mostram que seu desempenho em certas tarefas em química, matemática e codificação está no mesmo nível do o1 — que impressionou os pesquisadores quando foi lançado pela OpenAI em setembro .
“Isso é selvagem e totalmente inesperado”, escreveu Elvis Saravia, pesquisador de inteligência artificial (IA) e cofundador da empresa de consultoria em IA sediada no Reino Unido, DAIR.AI, no X.
O R1 se destaca por outro motivo. A DeepSeek, a start-up em Hangzhou que construiu o modelo, o lançou como ‘open-weight’, o que significa que os pesquisadores podem estudar e construir sobre o algoritmo. Publicado sob uma licença do MIT, o modelo pode ser reutilizado livremente, mas não é considerado totalmente de código aberto, porque seus dados de treinamento não foram disponibilizados.
“A abertura do DeepSeek é bastante notável”, diz Mario Krenn, líder do Artificial Scientist Lab no Instituto Max Planck para a Ciência da Luz em Erlangen, Alemanha. Em comparação, o1 e outros modelos construídos pela OpenAI em São Francisco, Califórnia, incluindo seu último esforço, o3 , são “essencialmente caixas-pretas”, ele diz.
O DeepSeek não divulgou o custo total do treinamento do R1, mas está cobrando das pessoas que usam sua interface cerca de um trigésimo do que o o1 custa para executar. A empresa também criou mini versões ‘destiladas’ do R1 para permitir que pesquisadores com poder de computação limitado brinquem com o modelo. Um “experimento que custou mais de £ 300 [US$ 370] com o o1, custou menos de US$ 10 com o R1”, diz Krenn. “Esta é uma diferença dramática que certamente desempenhará um papel em sua adoção futura.”
Modelos de desafio
O R1 faz parte de um boom em modelos de linguagem chinesa (LLMs) . Desmembrado de um fundo de hedge, o DeepSeek emergiu da relativa obscuridade no mês passado quando lançou um chatbot chamado V3, que superou os principais rivais, apesar de ter sido construído com um orçamento apertado. Especialistas estimam que custou cerca de US$ 6 milhões para alugar o hardware necessário para treinar o modelo, em comparação com mais de US$ 60 milhões para o Llama 3.1 405B da Meta, que usou 11 vezes os recursos de computação.
Parte do burburinho em torno do DeepSeek é que ele conseguiu fazer o R1 apesar dos controles de exportação dos EUA que limitam o acesso das empresas chinesas aos melhores chips de computador projetados para processamento de IA. “O fato de ele vir da China mostra que ser eficiente com seus recursos importa mais do que apenas a escala de computação”, diz François Chollet, um pesquisador de IA em Seattle, Washington.
O progresso do DeepSeek sugere que “a liderança percebida [que os] EUA já tiveram diminuiu significativamente”, escreveu Alvin Wang Graylin, especialista em tecnologia em Bellevue, Washington, que trabalha na empresa de tecnologia imersiva HTC, sediada em Taiwan, no X. “Os dois países precisam buscar uma abordagem colaborativa para construir IA avançada em vez de continuar com a atual abordagem de corrida armamentista sem vitória.”
Cadeia de pensamento
Os LLMs treinam em bilhões de amostras de texto, cortando-as em partes de palavras, chamadas tokens, e padrões de aprendizagem nos dados. Essas associações permitem que o modelo preveja tokens subsequentes em uma frase. Mas os LLMs são propensos a inventar fatos, um fenômeno chamado alucinação , e muitas vezes lutam para raciocinar sobre problemas.
Assim como o o1, o R1 usa um método de ‘cadeia de pensamento’ para melhorar a capacidade de um LLM de resolver tarefas mais complexas, incluindo, às vezes, retroceder e avaliar sua abordagem. O DeepSeek fez o R1 ‘ajustando’ o V3 usando aprendizado por reforço, que recompensou o modelo por chegar a uma resposta correta e por trabalhar em problemas de uma forma que delineasse seu ‘pensamento’.
Fonte: DeepSeek
Ter poder de computação limitado levou a empresa a “inovar algoritmicamente”, diz Wenda Li, pesquisadora de IA na Universidade de Edimburgo, Reino Unido. Durante o aprendizado por reforço, a equipe estimou o progresso do modelo em cada estágio, em vez de avaliá-lo usando uma rede separada. Isso ajudou a reduzir os custos de treinamento e execução, diz Mateja Jamnik, cientista da computação na Universidade de Cambridge, Reino Unido. Os pesquisadores também usaram uma arquitetura de ‘mistura de especialistas’, que permite que o modelo ative apenas as partes de si mesmo que são relevantes para cada tarefa.
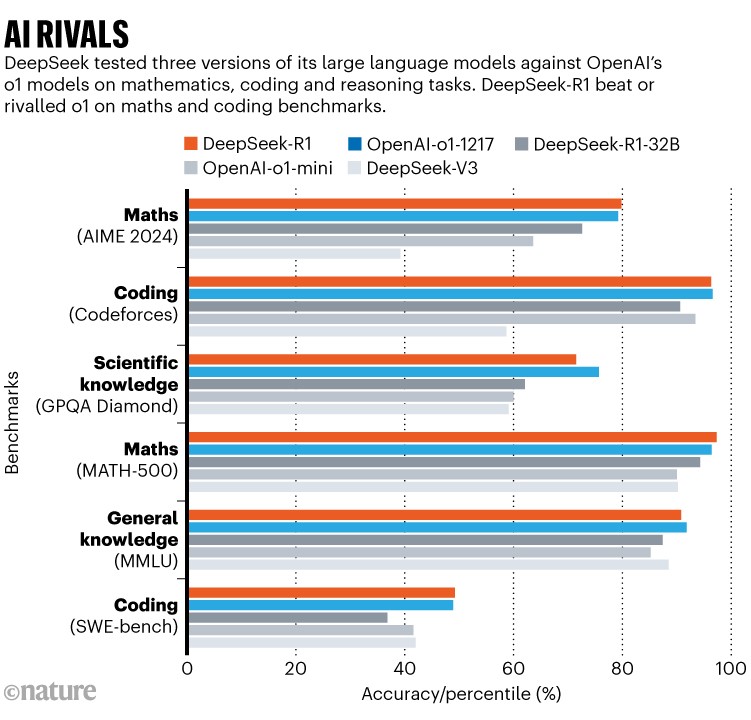
Em testes de benchmark, relatados em um artigo técnico que acompanha o modelo, o DeepSeek-R1 pontuou 97,3% no conjunto de problemas de matemática MATH-500 criado por pesquisadores da Universidade da Califórnia, Berkeley, e superou 96,3% dos participantes humanos em uma competição de programação chamada Codeforces. Isso está no mesmo nível das habilidades do o1; o o3 não foi incluído nas comparações (veja ‘IA rivais’).
É difícil dizer se os benchmarks capturam a verdadeira capacidade de um modelo de raciocinar ou generalizar, ou meramente sua proficiência em passar em tais testes. Mas como o R1 é aberto, sua cadeia de pensamento é acessível aos pesquisadores, diz Marco Dos Santos, um cientista da computação da Universidade de Cambridge. “Isso permite melhor interpretabilidade dos processos de raciocínio do modelo”, ele diz.
Os cientistas já estão testando as habilidades do R1. Krenn desafiou ambos os modelos rivais a classificar 3.000 ideias de pesquisa pelo quão interessantes elas são e comparou os resultados com classificações feitas por humanos. Nesta medida, o R1 teve um desempenho ligeiramente inferior ao do o1. Mas o R1 venceu o o1 em certos cálculos em óptica quântica, diz Krenn. “Isso é bastante impressionante.”
doi: https://doi.org/10.1038/d41586-025-00229-6
Fonte: Nature
